Standard harnesses read your code, not your storage. Claude Code, Cursor, and Codex don't know how many 10-Ks you have, which dataset they belong to, what's already been extracted, or how to dispatch the next pass without paying for it twice. DataChain does not replace them. Our skill and MCP add the missing storage context: typed datasets, lineage, checkpoint recovery, and delta updates that touch only what changed.
Resilience: never reprocess what already succeeded
Every pipeline runs as checkpointed stages. Delta updates touch only what changed.
- Resume from the exact stage of failure. No re-extraction of the 800K documents that already succeeded.
- Add 1,000 new filings to a 1M-document corpus by processing the new ones, not the whole corpus.
- 2.7× lower cost-of-failure ratio, measured. Vanilla Claude Code: failed runs cost 2.5× more than successful ones. With DataChain: 0.91× on average.
🧠 Brain: storage context the agent reads first
Knowledge Base catalogs what's in your storage: file counts, dataset memberships, schemas, lineage, and summaries from prior LLM passes. Dataset DB serves the typed records at warehouse speed. The agent reads what exists before generating code that processes what's missing.
- What's there: 10-Ks, contracts, disclosures, and due-diligence packs under one Pydantic schema.
- What's been done: extracted signals (covenants, risk factors, segment financials) as reusable decision assets, with version, lineage, and author on every materialized result.
- 100,000,000× cheaper to recall than to recompute, measured on a 1,500-document SEC 10-K corpus.
🦾 Hands: distributed execution from inside the chat
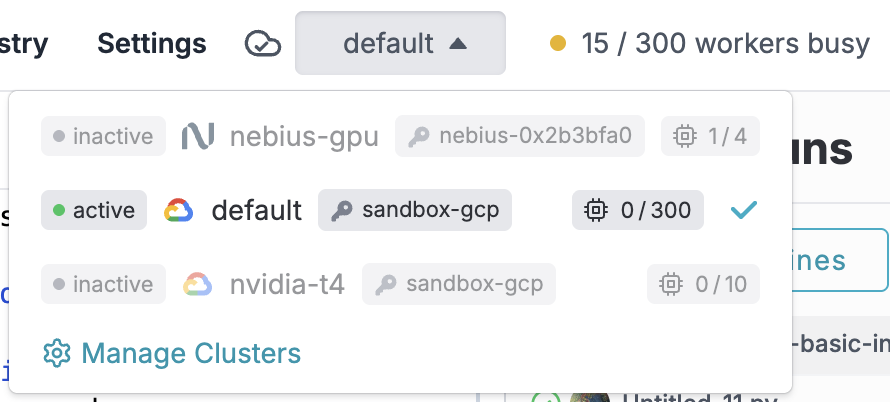
Standard agents run on the machine the chat lives on. With DataChain, the agent dispatches LLM extraction and embedding across hundreds of machines in your VPC: 300 CPUs on GCP, 10 T4 GPUs on GCP, 4 A100 GPUs on Nebius.
- Attach multiple clusters: CPU pools, GPU pools, high-memory pools.
- Scale from 1 to 1000+ machines from the SDK, no extra framework.
- DataChain manages the clusters for you. Workers spin up on demand, spin down when idle; you don't forget the 20 GPUs running over the weekend.
- Bytes never leave your storage. BYOC by default: compute runs in your AWS, GCP, or Azure account, behind your VPC, under your existing IAM.
Your agent goes from chat tool to research analyst with infrastructure access.
Research-measured proof
Two 2026 papers measure DataChain as a Claude Code extension on the exact corpus your team works with: SEC 10-K filings.
- 2.7× lower cost-of-failure ratio aggregate.
- 8.4× faster, 3.4× cheaper on the next question.
- 5× compounding savings across five sessions.
- +40 pp higher pass rate on reuse-rich tasks.
Code teams already see 10×. The data harness brings document AI into the same range.