Automate model deployment to Amazon SageMaker with the DVC Model Registry
The DVC Model Registry provides version registration and stage assignment as simple Git-based mechanisms to automate model deployment on any platform including Amazon SageMaker. Deploy real-time or serverless endpoints according to your need.







Model deployment to Amazon SageMaker from the DVC Model Registry
Amazon SageMaker from AWS is a popular platform for deploying Machine Learning models, showing up in almost all search results for the “best ML deployment platforms today.” So no doubt we’ve had many users ask us how they can deploy their models to SageMaker. If you would also like some help with this, you are in the right place.
With DVC pipelines and live metrics tracking using DVCLive and DVC Studio, iterating on your Machine Learning experiments is a simple process. And DVC Model Registry makes logging, tracking and deploying your trained models equally simple. In this article, we’ll walk you through how you can create a training pipeline that saves your trained models to AWS S3, and how you can then deploy the models to different environments in SageMaker automatically!
Interested in the final output right now? Here’s the code.
Prerequisites
To follow along, you’ll need to provision the following resources in AWS:
- An S3 bucket for saving your models
- Credentials with write access to the above S3 bucket. You’ll need this during training to save the models.
- AWS role with
AmazonS3FullAccessandAmazonSageMakerFullAccessfor reading the model files and deploying them to SageMaker.
First, why DVC + SageMaker?
DVC provides a unified way to manage your experiments, datasets, models and code. It works on top of Git, enabling you to apply the best software engineering and DevOps practices to your Machine Learning projects. It is also platform agnostic, which means you have full control over the choice of cloud services. And with a range of options for model deployment, including real-time and serverless endpoints, SageMaker is a great choice for hosting models of different sizes and inference frequencies.
Prequel: DVC push to save the models during training
DVC simplifies setting up reproducible pipelines that automatically save your model files during model training. Each stage in a DVC pipeline represents a distinct step in the training process. For each stage, you can specify hyperparameters and other dependencies, such as datasets or outputs of previous stages. You can also specify the outputs of each stage, such as metrics, plots, models, and other files. Learn more here.
Create a model file
The sagemaker stage of our pipeline creates a tar file (model.tar.gz) of
our trained model. We then mark this tar file as an output of the stage:
$ dvc stage add -n sagemaker … -o model.tar.gz …Note that it is not essential to create a separate sagemaker stage like we
did. You could also create the tar file as part of train or any other relevant
stage. In fact, you could even use the approach without a DVC pipeline, by
simply dvc adding the model files or logging them with the DVCLive
log_artifact() method. But we recommend using a DVC pipeline for easy
reproducibility of your ML experiments.
Configure DVC remote
Additionally, we’ve configured the default DVC remote to be our s3 bucket:
$ dvc remote add -d storage s3://dvc-public/remote/get-started-poolsThis means that whenever we run dvc push, the updated model tar file is
pushed to the s3 bucket.
Run the pipeline to save the model in S3
Now, every time we run our training pipeline an updated model tarfile is
generated, and we dvc push it to the remote S3 bucket. By storing large files
like the model tar file in remote storages such as s3, DVC makes it possible to
track them in Git, maintaining Git as the single source of truth for your
projects.
Track and manage model versions in DVC model registry
Our training script logs our model using the DVCLive log_artifact()
method, which creates an artifact entry of type model in a dvc.yaml file.
artifacts:
pool-segmentation:
path: ../../models/model.pkl
type: model
...Because of this, when we add the project to DVC Studio, the model appears in the model registry.
Note that there are other ways to register the model in the model registry - you
can add the model from the Studio UI or manually add it to the dvc.yaml
file.
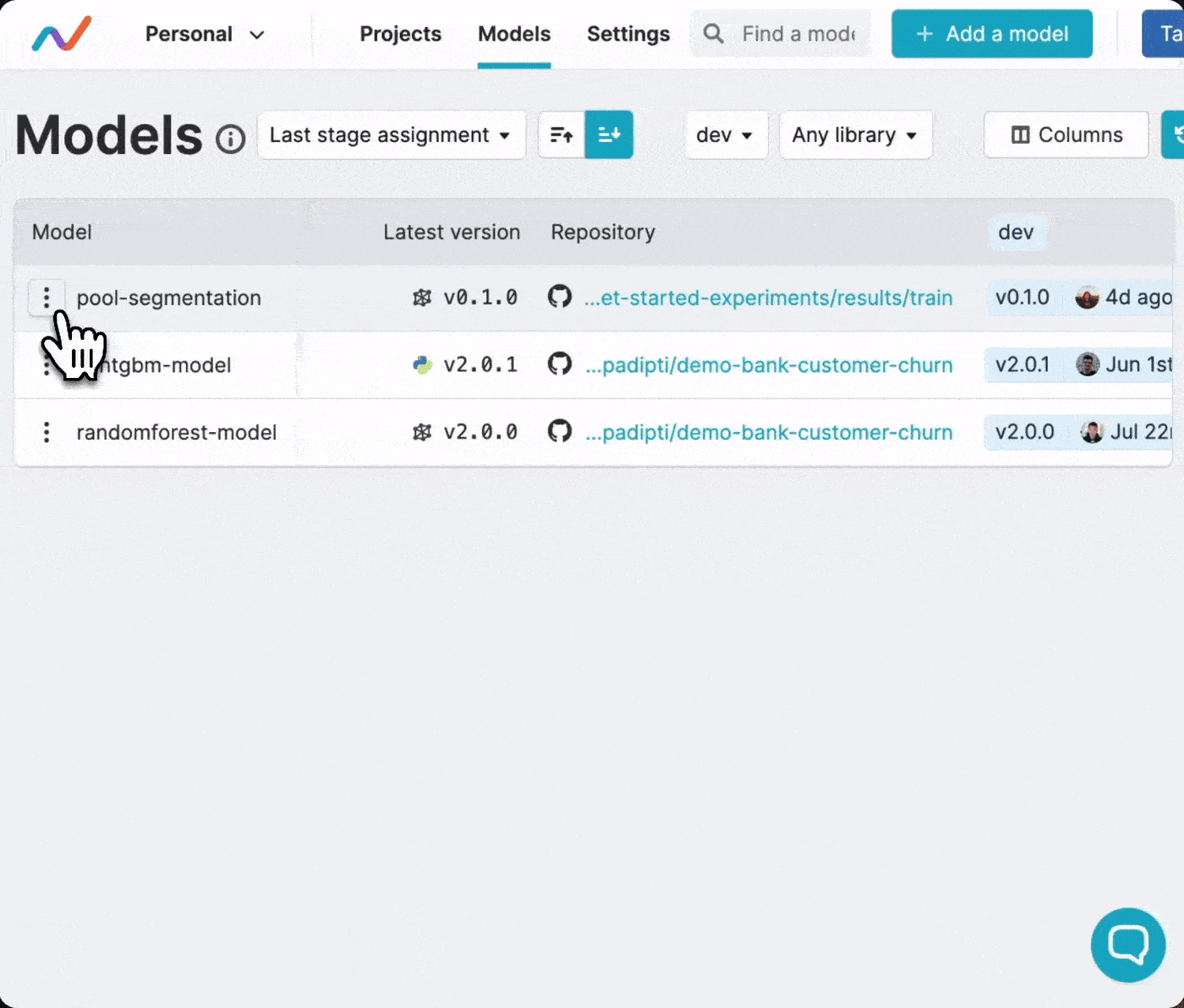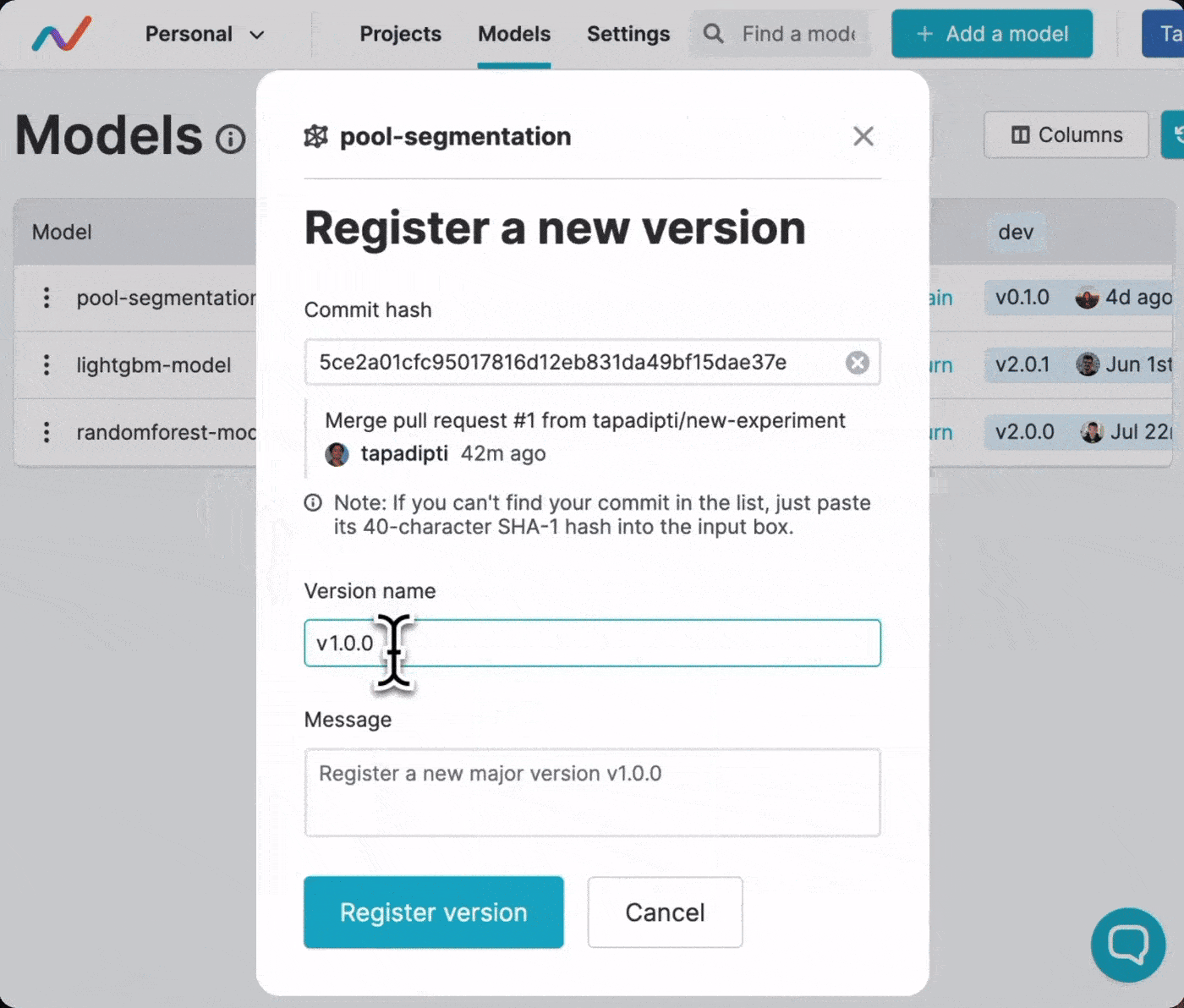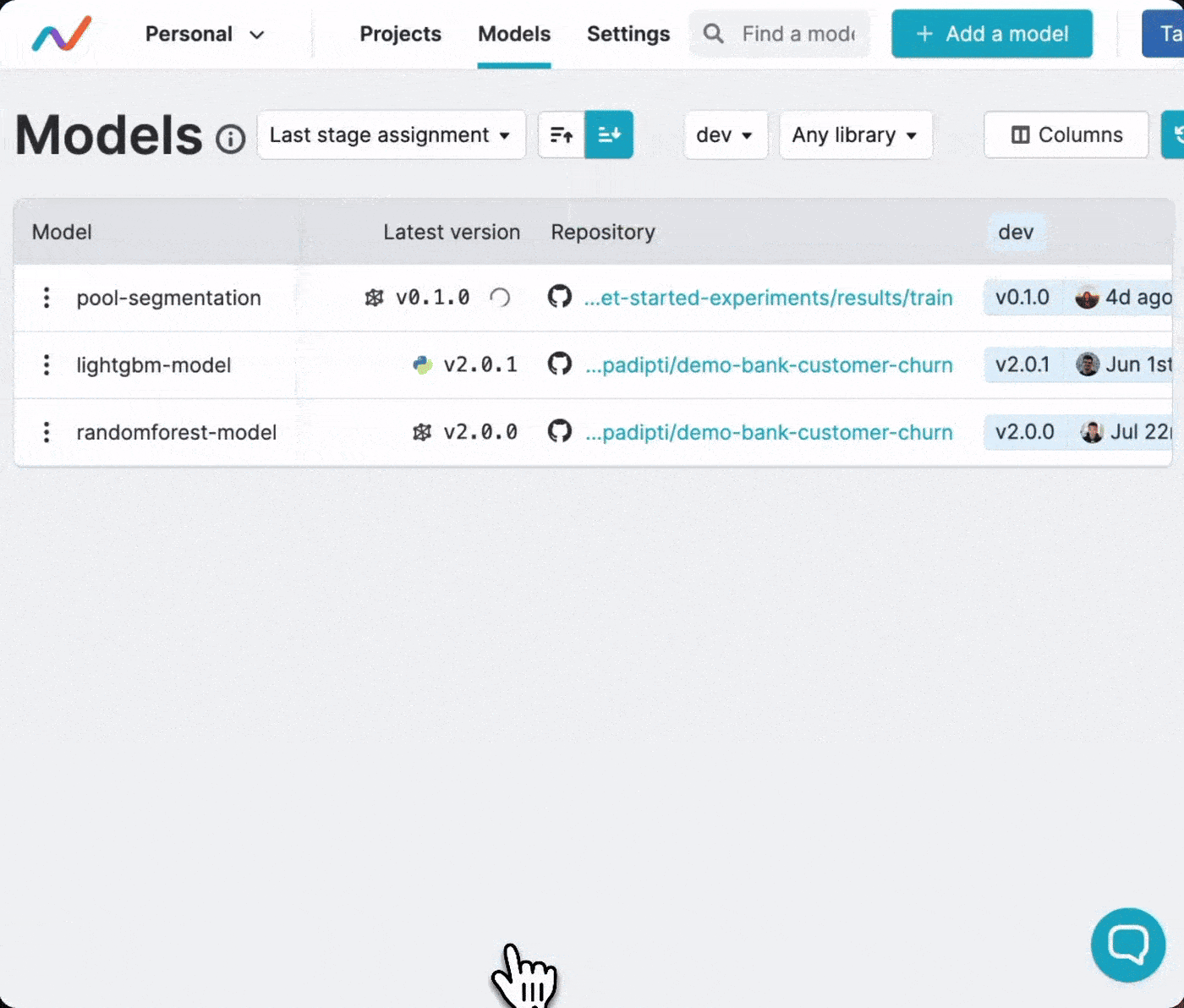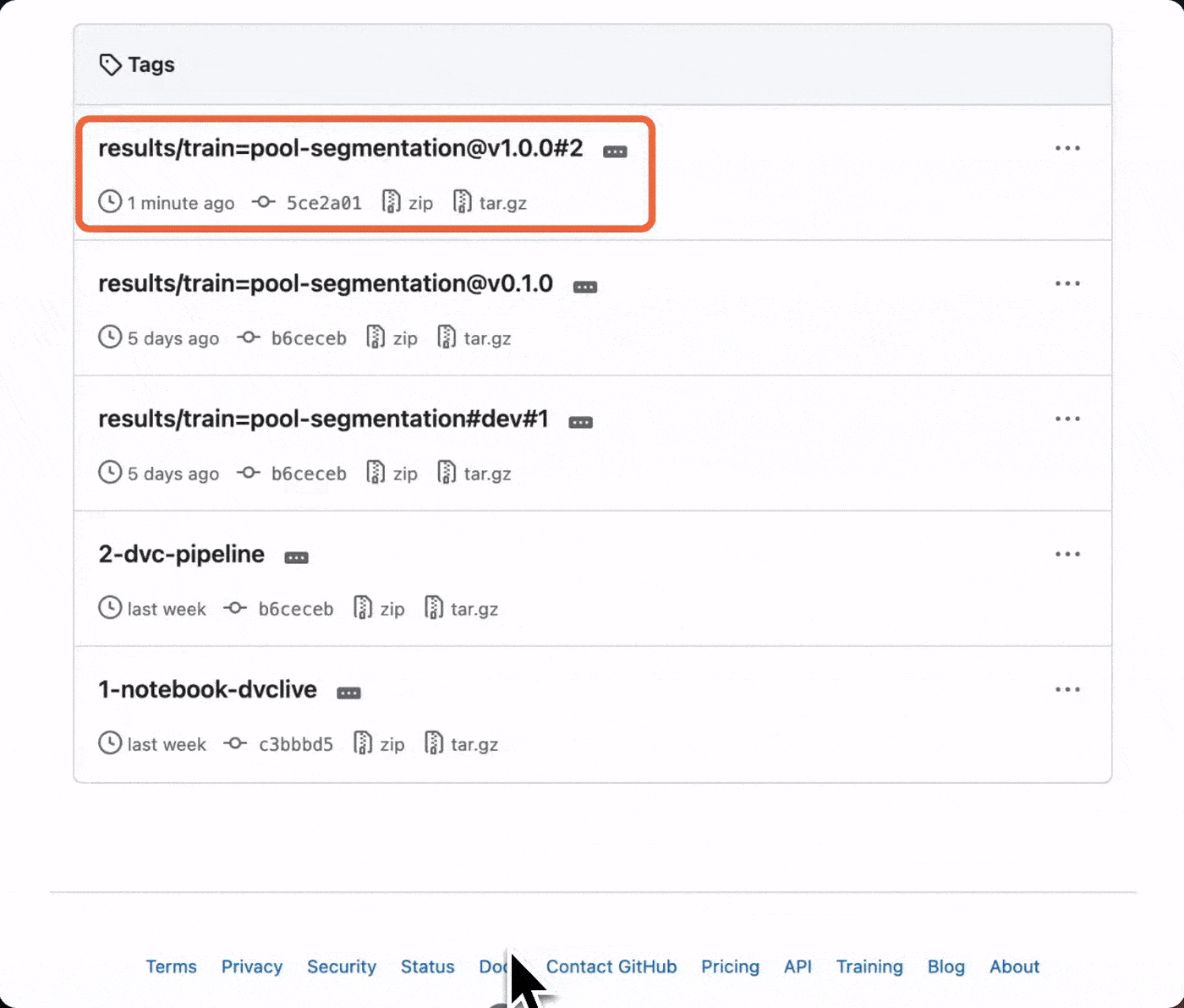
Once the model is registered in the model registry, you can assign version
numbers every time your ML experiment produces a model version that you like.
Use the Register version option to select the Git commit for the experiment
which produced the desired model version, and assign it a semantic version.
Every version registration is saved using specially formatted Git tags, which
you can find in the Git repository.
 Version
registration in the DVC Model Registry
Version
registration in the DVC Model Registry
Trigger model deployment with stage assignments
So far, you have saved your model versions in your Git repository (as Git tags)
and the actual model tar files in S3. Suppose you just registered version
1.0.0 of your model, and would like to deploy it to your dev environment so
that you and your team can evaluate its performance. The model registry
simplifies this too, by providing a mechanism to assign stages to model versions
and creating specially formatted Git tags representing this action.
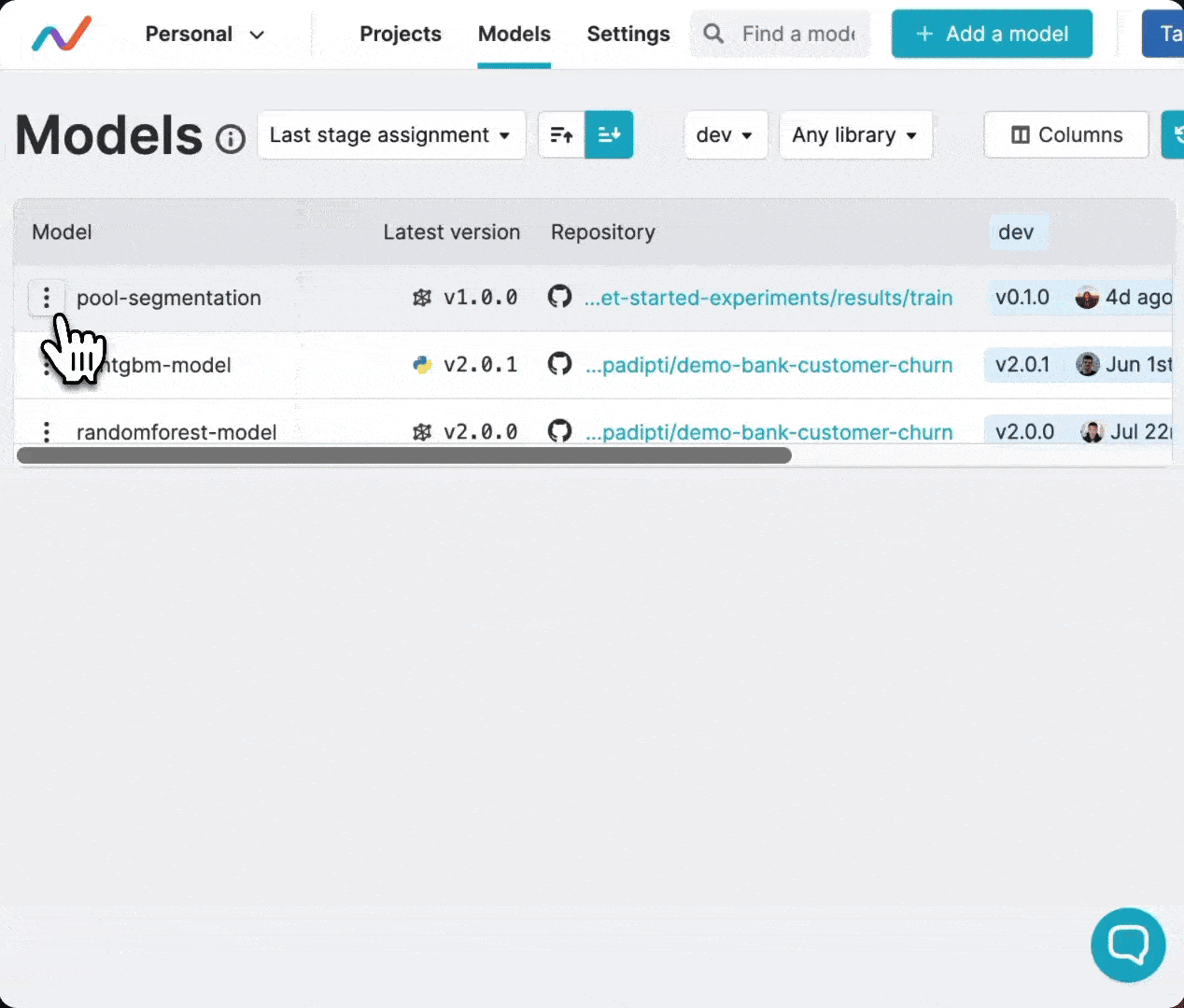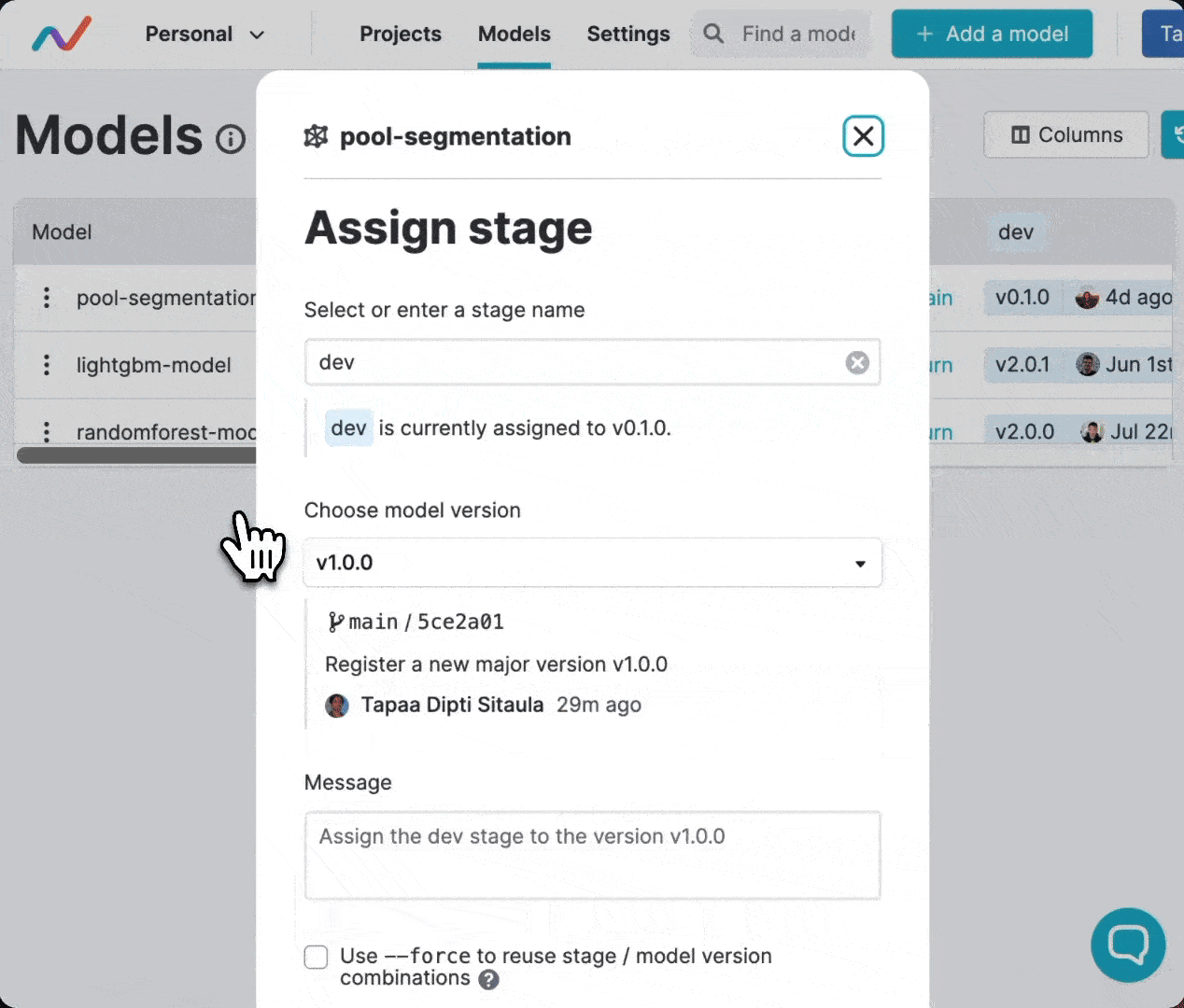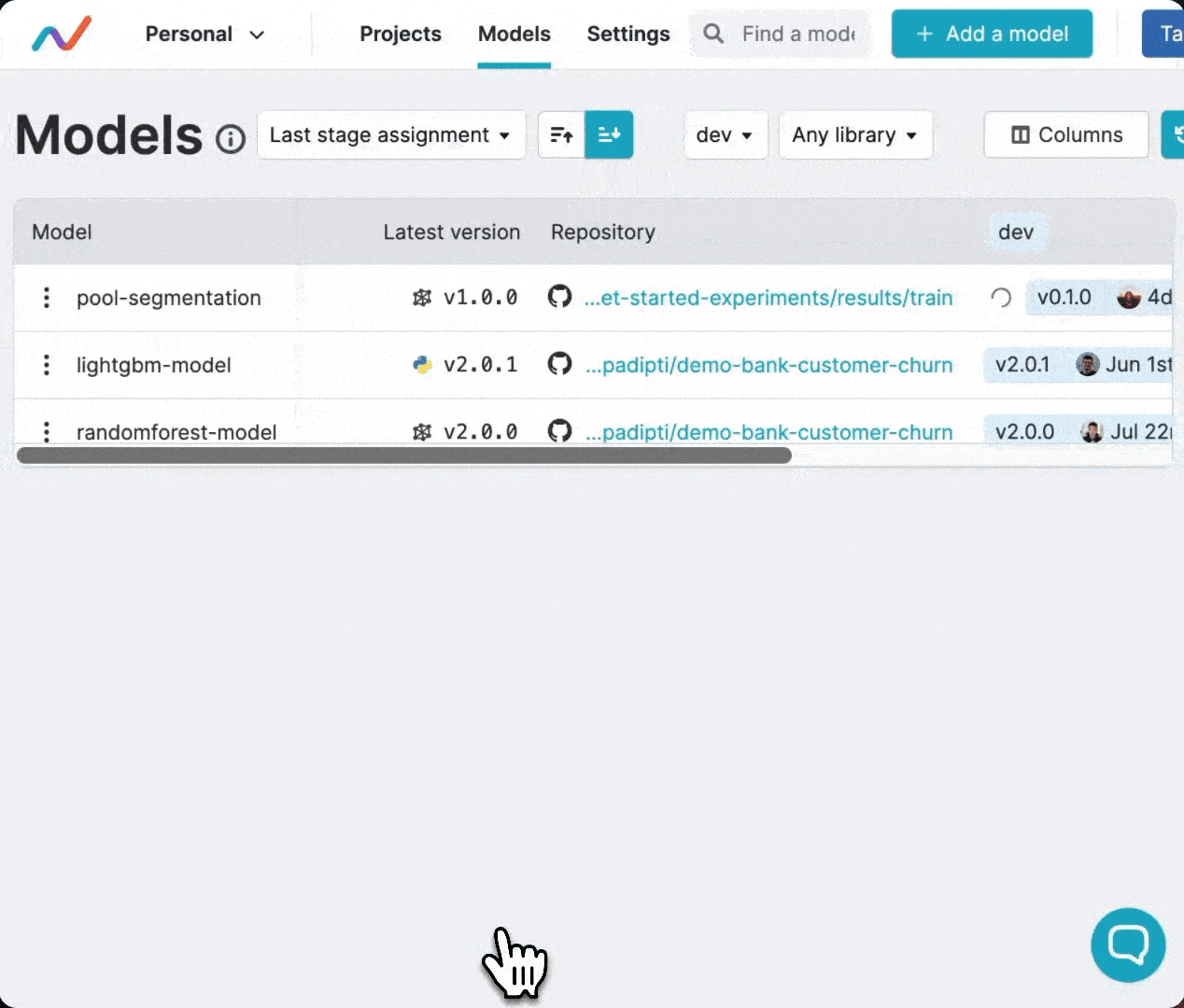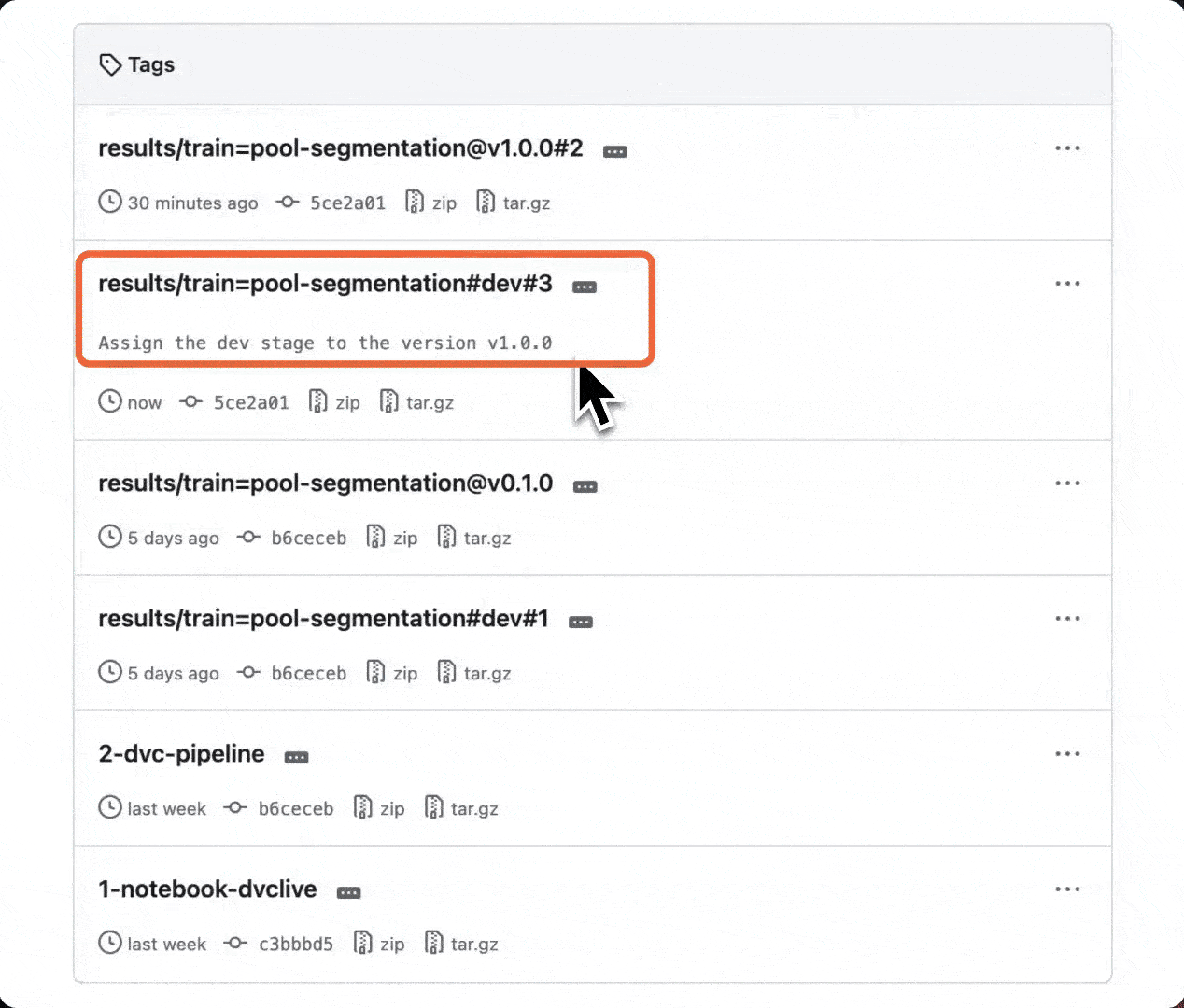 Stage
assignment in the DVC Model Registry
Stage
assignment in the DVC Model Registry
Since stage assignment also creates Git tags, you can write a CI/CD action that runs on Git tag push.
on:
push:
tags:
- 'results/train=pool-segmentation#*'This action parses the Git tags to determine the model, version and stage. DVC model registry internally uses GTO to save version registrations and stage assignments, and the Iterative GTO action can be used in your GitHub actions workflow to parse the Git tags:
uses: iterative/gto-action@v2This action produces the outputs shown below:
outputs:
event: ${{ steps.gto.outputs.event }} # whether the event is a version registration or a stage assignment
name: ${{ steps.gto.outputs.name }} # model name
stage: ${{ steps.gto.outputs.stage }}
version: ${{ steps.gto.outputs.version }}This action is available only in GitHub though; if you’re using GitLab,
Bitbucket or some other provider, you can use the gto check-ref
command to parse the Git tags, which follow this format.
Now, whenever you Assign stage to a model version, your CI/CD action
understands which version of which model was assigned which stage. Then, it can
use the dvc get –show-url command to determine the S3 path of the tar file
for the model version.
MODEL_DATA=$(dvc get --show-url . model.tar.gz)Finally, it can invoke the deployment script with appropriate inputs.
python sagemaker/deploy_model.py \
--name ${{ needs.parse.outputs.name }} \
--stage ${{ needs.parse.outputs.stage }} \
--version ${{ needs.parse.outputs.version }} \
--model_data $MODEL_DATA \
--role ${{ secrets.AWS_ROLE_TO_ASSUME }}This automates the model deployment process, which is very helpful if your model is expected to evolve constantly.
Next, we will explain the deployment script.
Deploy the model to SageMaker and run inference
So far, you’ve seen how you can
✅ create and run reproducible pipelines that save the model to S3,
✅ track and manage model versions in a web model registry, and
✅ assign stages to trigger model deployment.
The last step above specifies which model version should be deployed to which environment. Now let’s see how to actually
🔲 deploy the model, and
🔲 run inference on it.
A deployment in SageMaker is called an endpoint. When you deploy your model, you create or update an endpoint. And for running inference, you invoke the endpoint.
There are a few different ways to do the actual deployment, including the SageMaker Python SDK and the boto3 library. We have chosen to use the SageMaker Python SDK, which has a two-step process for deployment:
- create the SageMaker model bundle (click to see the code), and
- create the endpoint (click to see the code).
Note that if you do not expect your model to be constantly used for inference, you can create a serverless inference endpoint by specifying a serverless inference config (learn about the different inference options).
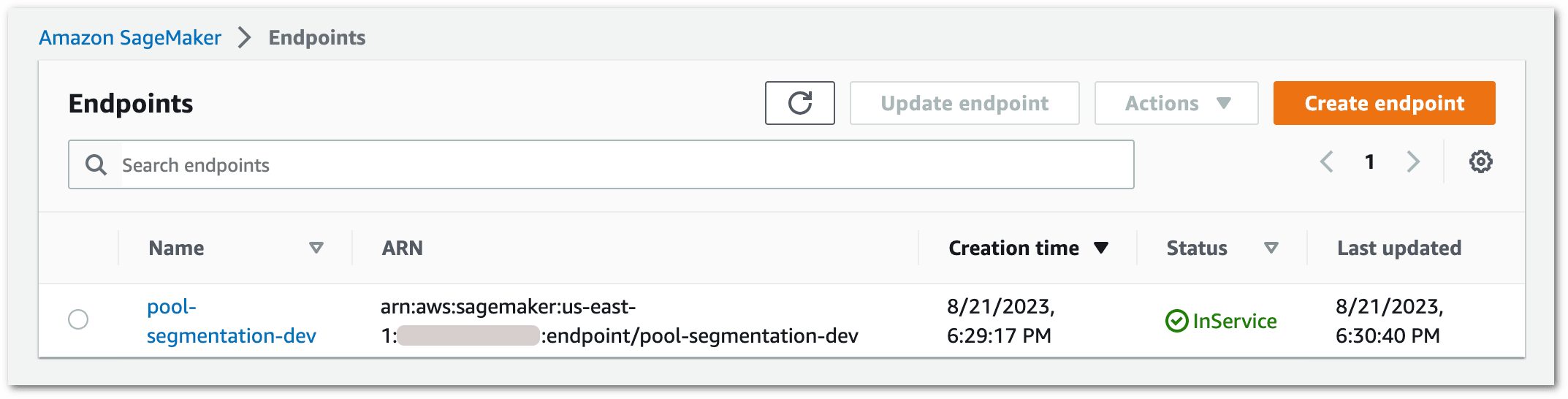
Once deployed, the endpoint status becomes InService in the AWS console.
Run inference
Now that your SageMaker deployment is ready, you can run inference using the
SageMaker predictor (for boto3, use invoke_endpoint()). Here is an
inference script that pre-processes your input, calls
inference, and applies the result mask to the input image to create the output
image, and saves the result.
Run this script with the following command:
$ python src/endpoint_prediction.py \
--img <jpg-file-path> \
--endpoint_name <endpoint-name> \
--output_path <output-folder>Here's my input image:

And the output identifying the swimming pools:

Now, your turn!
Let us know (reach out in Discord) if you run into any issues when trying to deploy your own model to SageMaker. We will be more than happy to help you figure it out!