




It is common for big codebases to grow to a complexity where it is nearly impossible for someone to tediously and flawlessly refactor things manually everywhere. The main problem with existing automated solutions (such as regex-based find-and-replace tools) is that they treat source code like a plain text document. This often results in false positives (tools making changes when they shouldn't) and/or false negatives (not changing what they should). This is primarily due to a lack of ability to truly encapsulate structural concepts of the programming language: syntax and grammar that are impossible to manifest in regexes.
This is where ASTs shine. They are the common building blocks of source code; produced by a parser that actually understands the language's syntax and creates a tree object where smaller parts (e.g. tokens) are ordered in a way that they are related by their syntactical meanings.
password = input("password? ")
if password == secrets.get("my_password"):
print("correct")
else:
print("incorrect")For example, the AST for the code above will look like this:
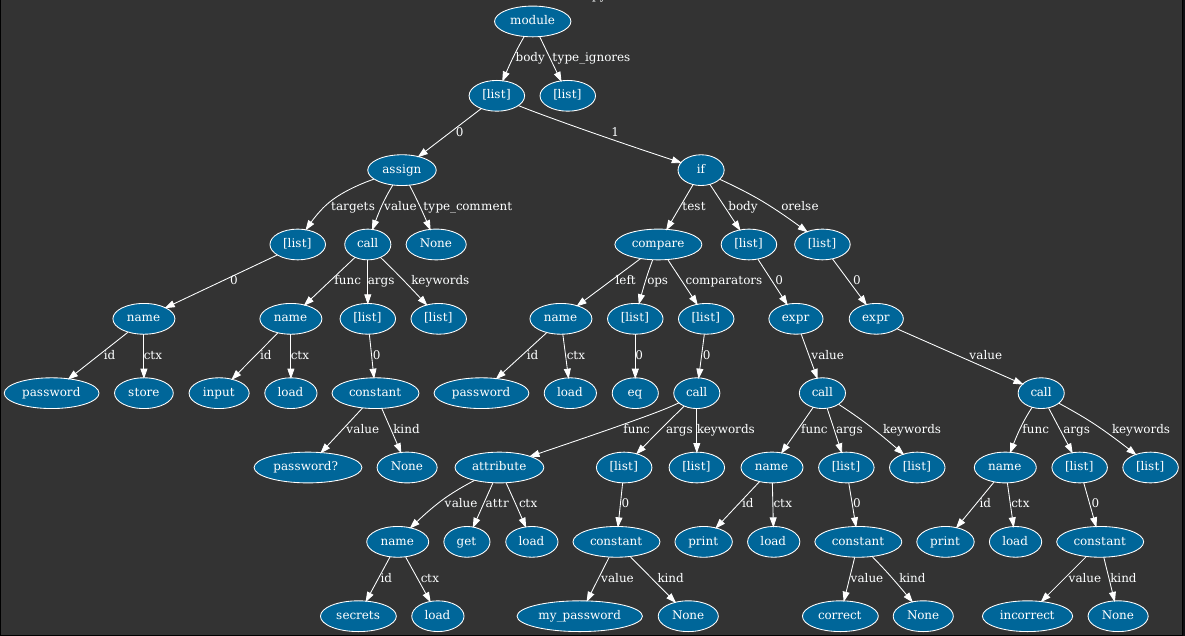
The top-most "root" node of this tree represents a single Python file. Each file
consists of a number of statements (e.g. function definitions, loops, etc.). For
our example we have only 2 statements: an assignment (to password), and an
if statement. Each of these statements in turn has child nodes as defined by
Python's ASDL.
Refactoring source code through ASTs
Refactor simplifies the process of matching ASTs. It then applies your transformations to these ASTs without touching the other parts of your source code.
For example, consider this code:
foo = [
1,
2
]
foo_2 = ['a', *foo]
if foo[0] >= 1:
assert secrets.get("foo") == fooAs a simple example, let's try to find and replace all instances of the foo
variable with bar… but without changing things inside strings or partial
matches like foo_2.
import ast
import refactorThe first thing we need to do is define a rule. Each rule is a class that
defines a single entrypoint (match())), takes AST nodes from the tree, and
either rejects them (via raising an AssertionError or just returning None)
or accepts them (via returning a refactor.Action).
class ReplaceFoo(refactor.Rule):
def match(self, node):Next, in the match() method, we will look for all Names (which is what the
actual identifier is wrapped in), and check whether its id is foo.
assert isinstance(node, ast.Name)
assert node.id == "foo"If any of these assertions fail, the function will terminate and the engine will
move to the next node in the tree. But if we have a match, we need to return
some sort of an action. The simplest thing we can return is a
refactor.ReplacementAction which takes this node and replaces it with the
given argument.
return refactor.ReplacementAction(
node,
ast.Name("bar", node.ctx)
)And that's it! To run this refactoring, we can simply create a CLI application
from our rules via refactor.run():
if __name__ == "__main__":
refactor.run(rules=[ReplaceFoo])If we run it on the file above, we will get this diff:
@@ -1,9 +1,9 @@
-foo = [
+bar = [
1,
2
]
-foo_2 = ['a', *foo]
+foo_2 = ['a', *bar]
-if foo[0] >= 1:
- assert secrets.get("foo") == foo
+if bar[0] >= 1:
+ assert secrets.get("foo") == barAll instances of the foo variable have been replaced, but items like foo_2
and "foo" are left alone as expected!
Going Deeper
Obviously not all refactorings are as simple as this, so refactor is equipped
with more features like different actions, observers and representatives for
context manager. If you are curious about these and more advanced features, be
sure to check out the
refactor documentation!