Post-modern AI Data Stack
The data stack generation is determined by a blend of emerging technologies and the applications they enable. We are now entering a new phase of data stack development, characterized by the adoption of foundational models, generative processes, faster time-to-value, and reduced data demands.





Image generated by DALL-E
Intro
It’s been more than 15 years since modern data processing began, yet if you ask about the next-generation stack, you’re unlikely to get clear answers. For instance, Perplexity summarizes the “post-modern” stack as an “evolution” that “enhances data reliability,” while Flux .1 Pro envisions a futuristic data center that looks like it’s only missing the film crew from The Matrix:


Combined, these two sources hint towards data post-modernism as a purely marketing ploy. Yet there are some things in the air that cannot be dismissed as mere exercise in corporate advertisement. Let me quickly demonstrate what I am talking about:
Case 1. Imagine you’re tasked with extracting “sales insights.” You have access to a wealth of corporate financials and market trends, along with hours of audio and video recordings of real customers interacting with sales reps.
Case 2. Now, picture yourself working for a marketplace, responsible for building a consumer-facing product catalog. You’re managing a database with hundreds of thousands of SKUs, stock levels, and product descriptions, plus millions of product images provided by vendors. These images are of variable quality, yet the catalog must conform to the common representational standards.
In both scenarios, it is likely the way you’d tackle these tasks would be vastly different from how you would have approached them just two years ago. This shift is a clear indication that something has changed, and a whiff of a quiet revolution in enterprise data processing.
So what exactly is going on?
Where we are now — the modern data stack
The hallmark of the modern data stack is its cloud-based architecture. This represents a massive leap from the local processing of earlier times, offering benefits such as limitless object storage, infinitely scalable computing power, and a dazzling array of modular components. Achieving this level of flexibility and scalability would have been nearly impossible under the old legacy systems.
So here are the main features of the modern data stack:
Cloud-based SaaS with sharing, versioning, and data governance. Scalable cloud data warehouses. Primarily SQL-based data transformations. ML and AI insights through integration with ML platforms.
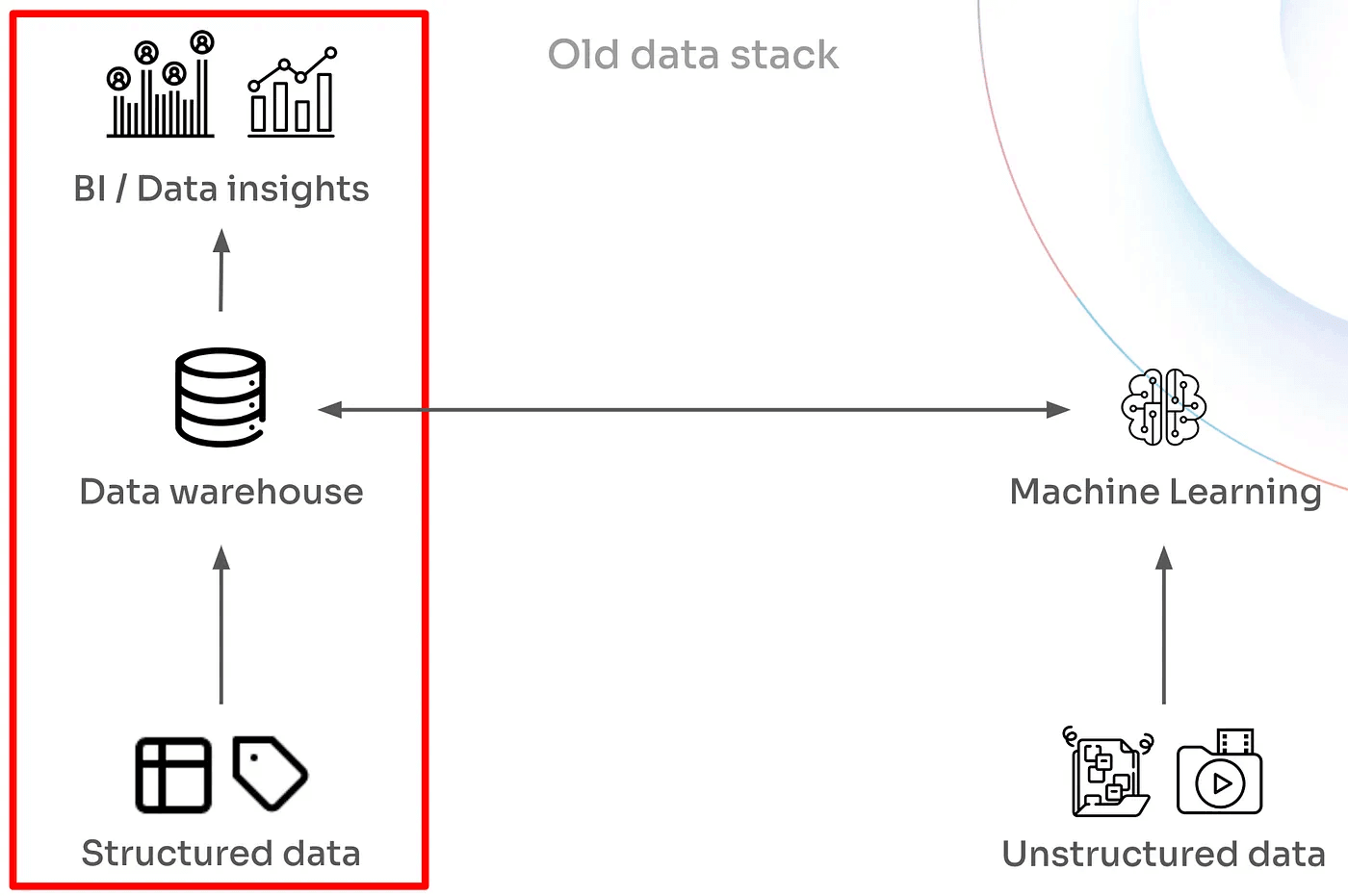
It quickly becomes evident that the majority of data processing in the “modern” stack takes place within the data warehouse, while machine learning operates more peripherally. A closer look at the AI/ML side of thinks reveals several key aspects:
Dozens of custom ML models extracting features and feeding them to ensembles of decision making models in the “bottoms-up” fashion. Data-hungry training algorithms. Long times required to train these ML models from scratch.
What we love about the modern stack
The modern stack ushered us into the era of “Big Data.” Its defining accomplishment is the ability to “find the needle in a haystack,” meaning it can extract meaningful insights from vast volumes of structured data.
A well-designed processing stack is also a hallmark of solid engineering practices, ensuring proper data provenance tracking and data governance. This is crucial, as the entire process relies heavily on data, making effective management and oversight essential for success.
What we hate about the modern stack
AI and ML are the relatively recent additions to modern stack, which is why it became permanently split into the older “SQL continent” and the newer “ML island”. This split drives a lot of complexity, including:
Engineering Qualifications: the official language of a data warehouse is SQL, the lingua franca of ML is Python. Good luck finding the engineers who can excel at both and interface two stack parts at once.
Resource Management: Data Warehouses need CPUs, ML models need GPU clusters — two distinct resource needs.
Large Unstructured Data: fitting multimodal objects like images and videos into traditional database rows is already tricky, and processing them through ML models adds another layer of complexity.
The modern stack isn’t built to seamlessly accommodate such diverse data types into uniform tables. However, the fact that there are many things we don’t love about something does not necessarily mean there is a revolution brewing up. A paradigm shift requires both the “pending need” and the “technology overhang."
The pull and the push towards the change
The “push” towards change often stems from the inefficiencies in current practices — many of which we’ve already discussed. The “pull,” on the other hand, comes from the tailwinds outside the data stack, and in recent years, these forces have been driven by the rapid advancements in foundational model capabilities.
What are the implications of these tailwinds? Foundational AI models offer the potential to significantly reduce:
• Time to value in analytics: No longer is there a need to train models from scratch, speeding up the experimentation.
• Big Data requirements: These are increasingly managed and amortized by the large model providers, lightening the burden on individual organizations.
• Personnel qualifications: Fine-tuning foundational models is far simpler than building ML models from the ground up, reducing the demand for specialized talent.
• ML infrastructure costs: Using APIs is cost-effective, especially when considering the savings from not needing to maintain inference infrastructure.
More crucially, these advancements are not just theoretical — they’ve been sufficiently proven to create a growing technology overhang, one that continues to build momentum at an accelerating pace.
The palliative solutions
As is often the case, the increasing divergence between enterprise data processing needs, which are shifting towards deep learning, has led to several intermediate solutions that attempt to bridge the gap. Among these:
• Data lakes: Designed to accommodate unstructured data by fitting it into table-like formats.
• ML “parks”: Add-ons attached to data warehouses to support machine learning processes.
• User-defined SQL functions: Allowing external ML/AI APIs to be called from within the warehouse environment.
While some of these solutions may seem effective in the short term, they are likely temporary fixes. In the long run, these stopgap measures will probably be phased out as more robust and integrated technologies emerge.
The generational change
Today’s modern data stack is heavily centered around data wrangling in SQL. But what would remain if deep learning models processing unstructured data became the predominant method of data processing? As it turns out, not much.
Certainly, vectorized operations on columns won’t disappear. However, a more significant shift is that data objects should be accessible directly from where they reside — in cloud storage. There’s no need to extract audio, store it as binary columns, and replicate it across every table iteration. “Storage as ground truth” is perfectly valid for handling unstructured data.
Even more crucially, there’s less reason to cling to SQL itself. SQL was designed to efficiently manipulate columnar data, but as data processing shifts toward deep learning models and APIs, the importance of column-oriented language diminishes. In this new paradigm, data warehouses can function seamlessly under the control of Python or another general data-oriented language.
Lastly, the concept of “Big Data” as we know it can easily fade. Large foundational models already possess rich representations of the world, and fine-tuning them for specific tasks requires far less data than we once believed necessary. Consider this: a factory worker doesn’t need to see millions of demonstrations to learn a new operation. Similarly, a sufficiently advanced foundational model can be specialized for various tasks in a top-down manner with far less effort than previously thought.
The post-modern stack
In light of our discussion, the shape of the post-modern data stack is surprisingly simple and intuitive.
Firstly, the post-modern stack eliminates the need for two distinct touchpoints for data access. While a data warehouse might still be used for backend operations, the frontend is streamlined, with a programming language like Python directly interacting with familiar object-oriented data structures like datasets. In this setup, data engineers can focus on AI/ML analytics without having to worry about translating these tasks into the underlying execution framework.
Secondly, unstructured data takes on a dominant role in this new architecture, rendering intricate access methods obsolete. Instead, cloud storage emerges as a perfectly adequate abstraction for storing unstructured data:
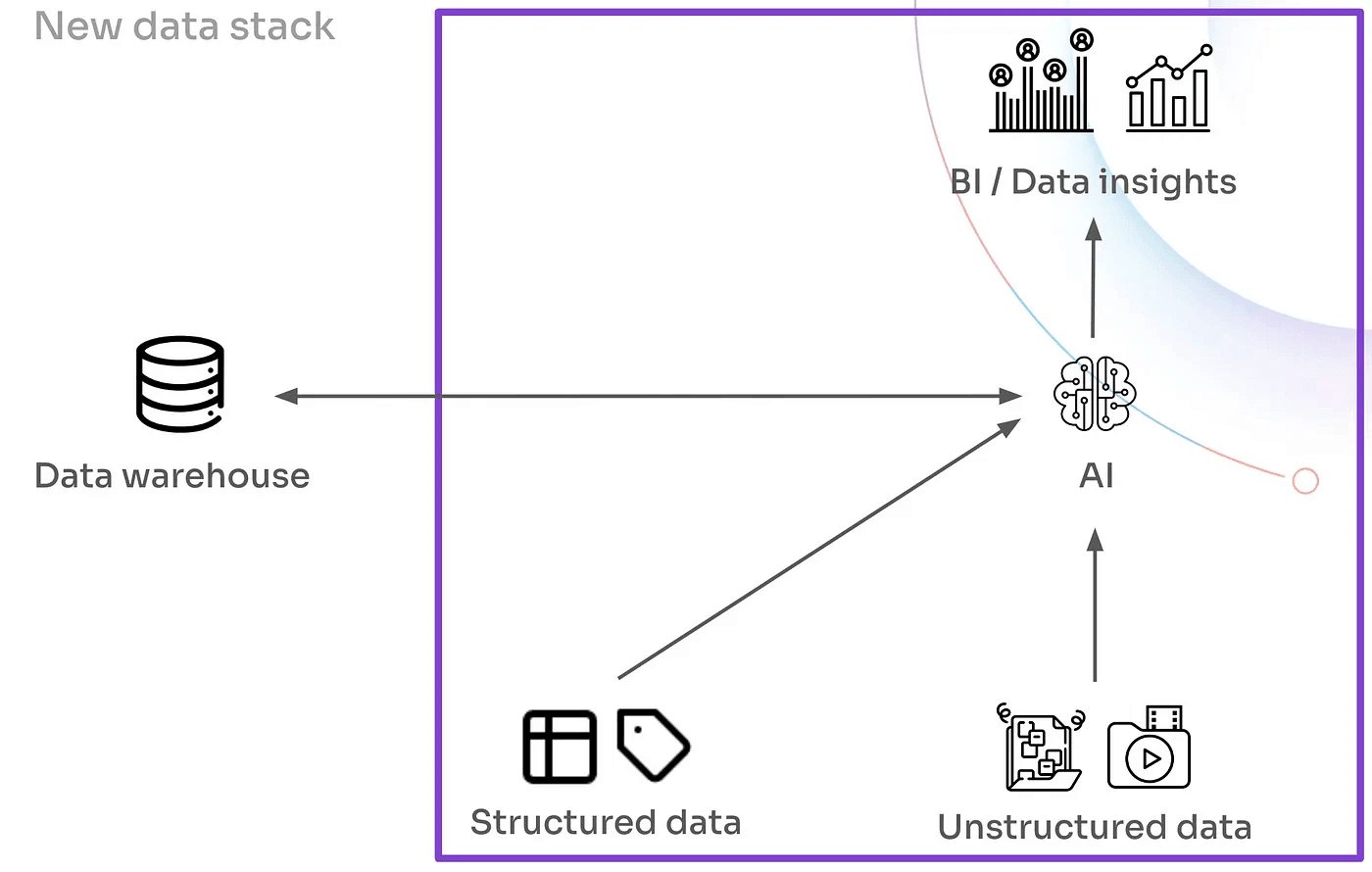
Lastly, while the majority of analysis and data transformation in the post-modern stack is handled by large foundational models, yet these models are not a core component of the stack itself.
This is because these models are provided by external vendors and are typically only fine-tuned by end-users for specific tasks. Whether hosted on-premises or in the cloud, the heavy lifting of training these large models is offloaded, meaning large model training is not a native part of the data stack. This allows the stack to remain lightweight and efficient, while leveraging the power of advanced AI without the burden of managing complex model training infrastructure.
Use cases revisited
We have opened this article with two use cases proved to be challenging in the current data processing paradigm. Let’s outline how trivial they are to solve in the post-modern world.
Case 1. Extracting sales insights.
The bulk of input data comes from audios and videos capturing sales transactions. As a result, key insights are derived from multimodal foundational models, which analyze customer reactions to specific sales tactics. These insights, when combined with financial transaction data from structured tables, provide a comprehensive context for large language model (LLM)-based sales efficiency analysis. This fusion of unstructured and structured data enables a more nuanced understanding of sales performance and customer behavior.
Case 2. Creating the product catalog.
In the old stack, product image curation required custom image classifiers, and data acquisition was an expensive process to gather additional product footage when needed.
In the new stack, however, the handling of product visuals is redefined as a generative task. Existing footage is now used to fine-tune generative image adapters, with a large generative AI (GenAI) network producing the necessary outputs. As a result, data engineers can shift their focus from the technical challenge of filtering through existing material to more strategic business requirements — such as ensuring the diversity, accuracy, and inclusivity of promotional content. This new approach greatly simplifies the process, allowing engineers to prioritize creative and ethical aspects over technical data wrangling and data acquisition processes.
Conclusion
In essence, the post-modern stack is about streamlining workflows by enabling direct interaction with data through foundational models and using cloud storage as the core layer for managing diverse data types. This approach simplifies the stack by reducing reliance on legacy systems and complex data management processes.
As is often the case with technological advancements, this future is already here, though not yet evenly distributed. Many AI-first companies have already moved away from SQL for data management and curation, embracing a more flexible, model-driven approach. Meanwhile, other enterprises are adopting a more cautious strategy, extending the transition period as they weigh the benefits and challenges of this shift.