Don't Just Track Your ML Experiments, Version Them
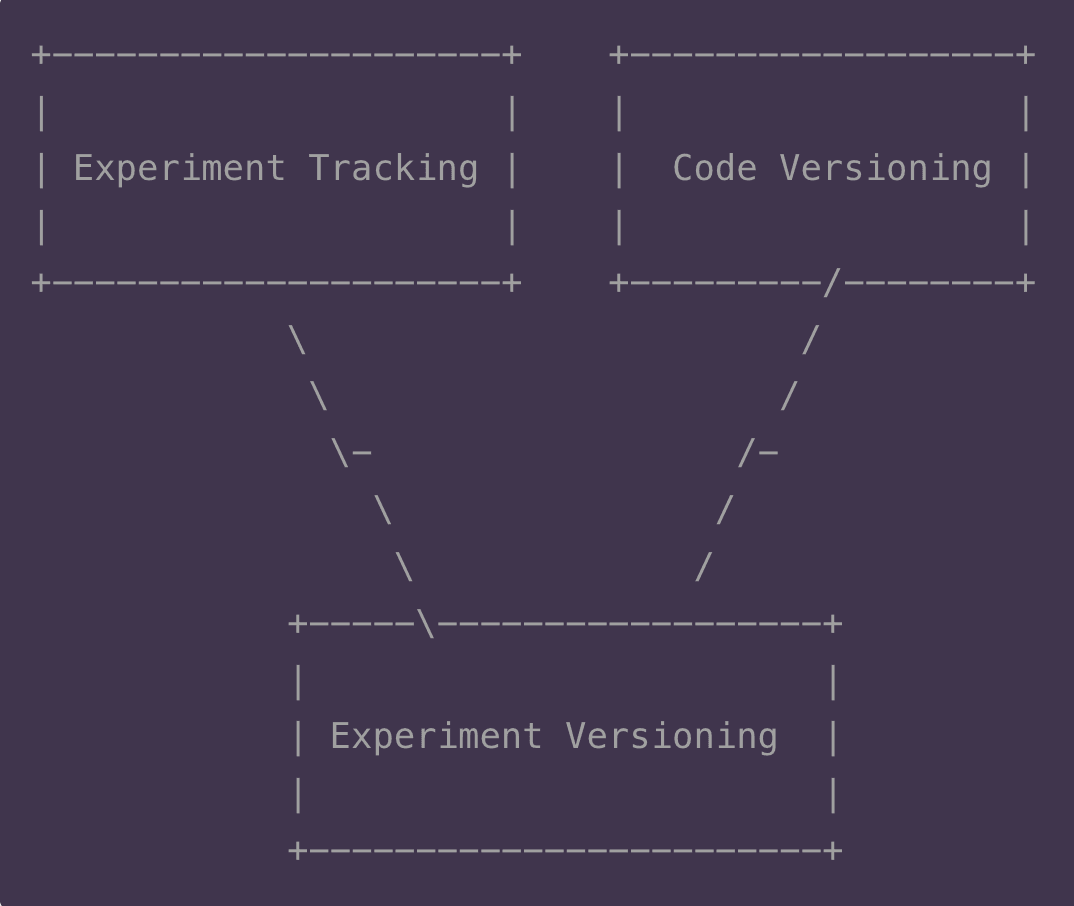
ML experiment versioning takes experiment tracking to the next level by adding the benefits of version control. Track experiments as code, make updates incrementally, and keep everything distributed to share however you want.





Keep your team organized with ML experiment versioning.
Experiment tracking tools help manage machine learning projects where version control tools like Git aren't enough. They log parameters and metrics, and they store artifacts like input data or model weights, so that you can reproduce experiments and retrieve results. They also provide a dashboard to navigate all this meta-information across lots of experiments.
Git can't manage or compare all that experiment meta-information, but it is still better for code. Tools like GitHub make distributed collaboration easy, and you can see incremental code changes. That's why experiments get split between Git for code and experiment tracking tools for meta-information (usually with a link in one or the other to keep track).
ML experiment versioning combines experiment tracking and version control. Instead of managing these separately, keep everything in one place and get the benefits of both, like:
- Experiments as code: Track meta-information in the repository and version it like code.
- Versioned reproducibility: Save and restore experiment state, and track changes to only execute what's new.
- Distributed experiments: Organize locally and choose what to share, reusing your existing repo setup.
ML Experiments as Code
Experiment versioning treats experiments as code. It saves all metrics, hyperparameters, and artifact information in text files that can be versioned by Git (DVC data versioning backs up the artifacts themselves anywhere). You do not need a centralized database or online services. Git becomes a store for experiment meta-information.
You can choose your own file formats and paths, which you can configure in DVC:
$ dvc exp init -i
This command will guide you to set up a default stage in dvc.yaml.
See https://dvc.org/doc/user-guide/project-structure/pipelines-files.
DVC assumes the following workspace structure:
├── data
├── metrics.json
├── models
├── params.yaml
├── plots
└── src
Command to execute: python src/train.py
Path to a code file/directory [src, n to omit]: src/train.py
Path to a data file/directory [data, n to omit]: data/images/
Path to a model file/directory [models, n to omit]:
Path to a parameters file [params.yaml, n to omit]:
Path to a metrics file [metrics.json, n to omit]:
Path to a plots file/directory [plots, n to omit]: logs.csvOnce you set up your repo in this structure, you start to see the benefits of this approach. Experiment meta-information lives in readable files that are always available, and your code can stay clean. You can read, save, and version your meta-information:
$ cat params.yaml
train:
epochs: 10
model:
conv_units: 128$ cat metrics.json
{"loss": 0.24310708045959473, "acc": 0.9182999730110168}You can see what changed in parameters, code, or anything else:
$ git diff HEAD~1 -- params.yaml
diff --git a/params.yaml b/params.yaml
index baad571a2..57d098495 100644
--- a/params.yaml
+++ b/params.yaml
@@ -1,5 +1,5 @@
train:
epochs: 10
-model:
- conv_units: 16
+model:
+ conv_units: 128With DVC, you can even compare lots of experiments from the terminal like you would in a dashboard:
$ dvc exp show
─────────────────────────────────────────────────────────────────────────────────────────────
Experiment Created loss acc train.epochs model.conv_units
─────────────────────────────────────────────────────────────────────────────────────────────
workspace - 0.25183 0.9137 10 64
mybranch Oct 23, 2021 - - 10 16
├── 9a4ff1c [exp-333c9] 10:40 AM 0.25183 0.9137 10 64
├── 138e6ea [exp-55e90] 10:28 AM 0.25784 0.9084 10 32
└── 51b0324 [exp-2b728] 10:17 AM 0.25829 0.9058 10 16
─────────────────────────────────────────────────────────────────────────────────────────────Versioned reproducibility
One reason you need to track all this meta-information is to reproduce your experiment. Experiment tracking databases save the artifacts, but you still need to put them all back in the right place. Since experiment versioning keeps all the meta-information in your repo, you can restore the experiment state exactly as it was in your workspace. DVC saves the state of the experiment, and it can restore it for you:
$ dvc exp apply exp-333c9
Changes for experiment 'exp-333c9' have been applied to your current workspace.Reproducibility is nice, but data drift, new business requirements, bug fixes, etc. all mean running a slightly modified experiment. You don't have time to always start from scratch. Versioned reproducibility means tracking changes to the experiment state. DVC can determine what changes were introduced by the experiment and only run what's necessary. It only saves those changes, so you don't waste time or storage on duplicate copies of data.
$ dvc exp run --set-param model.conv_units=128
'data/images.tar.gz.dvc' didn't change, skipping
Stage 'extract' didn't change, skipping
Running stage 'train':
> python3 src/train.py
79/79 [==============================] - 1s 14ms/step - loss: 0.2552 - acc: 0.9180
Updating lock file 'dvc.lock'
Reproduced experiment(s): exp-be916
Experiment results have been applied to your workspace.
To promote an experiment to a Git branch run:
dvc exp branch <exp> <branch>Distributed Experiments
Experiment tracking tools log experiments to a central database and show them in a dashboard. This makes it easy to share them with teammates and compare experiments. However, it introduces a problem - in an active experimentation phase, you may create hundreds of experiments. Team members may be overwhelmed, and the tool loses one of its core purposes - sharing experiments between team members.
Experiment versioning piggybacks on Git and its distributed nature. All the experiments you run are stored in your local repo, and only the best experiments are promoted to the central repo (GitHub for example) to share with teammates. Distributed experiments are shared with the same people as your code repo, so you don't need to replicate your project permissions or worry about security risks.
With DVC, you can push experiments just like Git branches, giving you flexibility to share whatever, whenever, and wherever you choose:
$ dvc exp push origin exp-333c9
Pushed experiment 'exp-333c9'to Git remote 'origin'.What Next?
These enhancements can have powerful ripple effects for fast-moving, complex, collaborative ML projects. There are parallels to the history of version control. Git's distributed nature and incremental change tracking were major advances over the centralized, file-based version control systems of previous generations. Experiment versioning can similarly advance the next generation of experiment tracking.
ML experiment versioning is still in its early days. Look out for future announcements about:
- Deep learning features like live monitoring and checkpointing.
- Visualizing and comparing experiment results in other tools like VS Code and DVC Studio.
What do you want to see for the next generation of experiment tracking? Join our upcoming meetup to discuss, join our Discord community, or let us know in the comments!