DVC 2.0 Pre-Release
The new release is a result of our learning from our users. There are four major features coming: 🔗 ML pipeline templating and iterative foreach stages 🧪 Lightweight ML experiments 📍 ML model checkpoints 📈 Dvc-live - new open-source library for metrics logging





DVC 2.0 Pre-Release
Install
First things first. You can install the 2.0 pre-release from the master branch in our repo (instruction here) or through pip:
$ pip install --upgrade --pre dvcML pipelines parameterization and foreach stages
After introducing the multi-stage pipeline file dvc.yaml, it was quickly
adopted among our users. The DVC team got tons of positive feedback from them,
as well as feature requests.
Pipeline parameters from vars
The most requested feature was the ability to use parameters in dvc.yaml. For
example. So, you can pass the same seed value or filename to multiple stages in
the pipeline.
vars:
train_matrix: train.pkl
test_matrix: test.pkl
seed: 20210215
...
stages:
process:
cmd: python process.py \
--seed ${seed} \
--train ${train_matrix} \
--test ${test_matrix}
outs:
- ${test_matrix}
- ${train_matrix}
...
train:
cmd: python train.py ${train_matrix} --seed ${seed}
deps:
- ${train_matrix}Also, it gives an ability to localize all the important parameters in a single
vars block and play with them. This is a natural thing to do for scenarios
like NLP or when hyperparameter optimization is happening not only in the model
training code but in the data processing as well.
Pipeline parameters from params files
It is quite common to define pipeline parameters in a config file or a
parameters file (like params.yaml) instead of in the pipeline file dvc.yaml
itself. These parameters defined in params.yaml can also be used in
dvc.yaml.
# params.yaml
models:
us:
thresh: 10
filename: 'model-us.hdf5'# dvc.yaml
stages:
build-us:
cmd: >-
python script.py
--out ${models.us.filename}
--thresh ${models.us.thresh}
outs:
- ${models.us.filename}DVC properly tracks params dependencies for each stage starting from the
previous DVC version 1.0. See the
--params option
of dvc run for more details.
Iterating over params with foreach stages
Iterating over params was a frequently requested feature. Now users can define multiple similar stages with a templatized command.
stages:
build:
foreach:
gb:
thresh: 15
filename: 'model-gb.hdf5'
us:
thresh: 10
filename: 'model-us.hdf5'
do:
cmd: >-
python script.py --out ${item.filename} --thresh ${item.thresh}
outs:
- ${item.filename}Lightweight ML experiments
DVC uses Git versioning as the basis for ML experiments. This solid foundation makes each experiment reproducible and accessible from the project's history. This Git-based approach works very well for ML projects with mature models when only a few new experiments per day are run.
However, in more active development, when dozens or hundreds of experiments need
to be run in a single day, Git creates overhead — each experiment run requires
additional Git commands git add/commit, and comparing all experiments is
difficult.
We introduce lightweight experiments in DVC 2.0! This is how you can auto-track ML experiments without any overhead from ML engineers.
⚠️ Note, our new ML experiment features (dvc exp) are experimental in the
coming release. This means that the commands might change a bit in the following
minor releases.
dvc exp run can run an ML experiment with a new hyperparameter from
params.yaml while dvc exp diff shows metrics and params difference:
$ dvc exp run --set-param featurize.max_features=3000
Reproduced experiment(s): exp-bb55c
Experiment results have been applied to your workspace.
$ dvc exp diff
Path Metric Value Change
scores.json auc 0.57462 0.0072197
Path Param Value Change
params.yaml featurize.max_features 3000 1500More experiments:
$ dvc exp run --set-param featurize.max_features=4000
Reproduced experiment(s): exp-9bf22
Experiment results have been applied to your workspace.
$ dvc exp run --set-param featurize.max_features=5000
Reproduced experiment(s): exp-63ee0
Experiment results have been applied to your workspace.
$ dvc exp run --set-param featurize.max_features=5000 \
--set-param featurize.ngrams=3
Reproduced experiment(s): exp-80655
Experiment results have been applied to your workspace.In the examples above, hyperparameters were changed with the --set-param
option, but you can make these changes by modifying the params file instead. In
fact any code or data files can be changed and dvc exp run will capture the
variations.
See all the runs:
$ dvc exp show --no-pager --no-timestamp \
--include-params featurize.max_features,featurize.ngrams ─────────────────────────────────────────────────────────────────────
Experiment auc featurize.max_features featurize.ngrams
─────────────────────────────────────────────────────────────────────
workspace 0.56359 5000 3
master 0.5674 1500 2
├── exp-80655 0.56359 5000 3
├── exp-63ee0 0.5515 5000 2
├── exp-9bf22 0.56448 4000 2
└── exp-bb55c 0.57462 3000 2
─────────────────────────────────────────────────────────────────────Under the hood, DVC uses Git to store the experiments' meta-information. A
straight-forward implementation would create visible branches and auto-commit in
them, but that approach would over-pollute the branch namespace very quickly. To
avoid this issue, we introduced custom Git references exps, the same way as
GitHub uses custom references pulls to track pull requests (this is an
interesting technical topic that deserves a separate blog post). Below you can
see how it works.
No artificial branches, only custom references exps (do not worry if you don't
understand this part - it is an implementation detail):
$ git branch
* master
$ git show-ref
5649f62d845fdc29e28ea6f7672dd729d3946940 refs/exps/exec/EXEC_APPLY
5649f62d845fdc29e28ea6f7672dd729d3946940 refs/exps/exec/EXEC_BRANCH
5649f62d845fdc29e28ea6f7672dd729d3946940 refs/exps/71/67904d89e116f28daf7a6e4c0878268117c893/exp-80655
f16e7b7c804cf52d91d1d11850c15963fb2a8d7b refs/exps/97/d69af70c6fb4bc59aefb9a87437dcd28b3bde4/exp-63ee0
0566d42cddb3a8c4eb533f31027f0febccbbc2dd refs/exps/91/94265d5acd847e1c439dd859aa74b1fc3d73ad/exp-bb55c
9bb067559583990a8c5d499d7435c35a7c9417b7 refs/exps/49/5c835cd36772123e82e812d96eabcce320f7ec/exp-9bf22The best experiment can be promoted to the workspace and committed to Git.
$ dvc exp apply exp-bb55c
$ git add .
$ git commit -m 'optimize max feature size'Alternatively, an experiment can be promoted to a branch (big_fr_size branch
in this case):
$ dvc exp branch exp-80655 big_fr_size
Git branch 'big_fr_size' has been created from experiment 'exp-c695f'.
To switch to the new branch run:
git checkout big_fr_sizeRemove all the experiments that were not used:
$ dvc exp gc --workspace --forceModel checkpoints
ML model checkpoints are an essential part of deep learning. ML engineers prefer to save the model files (or weights) at checkpoints during a training process and return back when metrics start diverging or learning is not fast enough.
The checkpoints create a different dynamic around ML modeling process and need a special support from the toolset:
- Track and save model checkpoints (DVC outputs) periodically, not only the final result or training epoch.
- Save metrics corresponding to each of the checkpoints.
- Reuse checkpoints - warm-start training with an existing model file, corresponding code, dataset version and metrics.
This new behavior is supported in DVC 2.0. Now, DVC can version all your checkpoints with corresponding code and data. It brings the reproducibility of DL processes to the next level - every checkpoint is reproducible.
This is how you define checkpoints with live-metrics:
$ dvc stage add -n train \
-d users.csv -d train.py \
-p dropout,epochs,lr,process \
--checkpoint model.h5 \
--live logs \
python train.py
Creating 'dvc.yaml'
Adding stage 'train' in 'dvc.yaml'Note, we use dvc stage add command instead of dvc run. Starting from DVC 2.0
we begin extracting all stage specific functionality under dvc stage umbrella.
dvc run is still working, but will be deprecated in the following major DVC
version (most likely in 3.0).
Start the training process and interrupt it after 5 epochs:
$ dvc exp run
'users.csv.dvc' didn't change, skipping
Running stage 'train':
> python train.py
...
^CTraceback (most recent call last):
...
KeyboardInterruptNavigate in checkpoints:
$ dvc exp show --no-pager --no-timestamp ──────────────────────────────────────────────────────────────────────
Experiment step loss accuracy val_loss … epochs …
──────────────────────────────────────────────────────────────────────
workspace 4 2.0702 0.30388 2.025 … 5 …
master - - - - … 5 …
│ ╓ exp-e15bc 4 2.0702 0.30388 2.025 … 5 …
│ ╟ 5ea8327 4 2.0702 0.30388 2.025 … 5 …
│ ╟ bc0cf02 3 2.1338 0.23988 2.0883 … 5 …
│ ╟ f8cf03f 2 2.1989 0.17932 2.1542 … 5 …
│ ╟ 7575a44 1 2.2694 0.12833 2.223 … 5 …
├─╨ a72c526 0 2.3416 0.0959 2.2955 … 5 …
──────────────────────────────────────────────────────────────────────Each of the checkpoints above is a separate experiment with all data, code,
paramaters and metrics. You can use the same dvc exp apply command to extract
any of these.
Another run continues this process. You can see how accuracy metrics are increasing - DVC does not remove the model/checkpoint and training code trains on top of it:
$ dvc exp run
Existing checkpoint experiment 'exp-e15bc' will be resumed
...
^C
KeyboardInterrupt
$ dvc exp show --no-pager --no-timestamp ──────────────────────────────────────────────────────────────────────
Experiment step loss accuracy val_loss … epochs …
──────────────────────────────────────────────────────────────────────
workspace 9 1.7845 0.58125 1.7381 … 5 …
master - - - - … 5 …
│ ╓ exp-e15bc 9 1.7845 0.58125 1.7381 … 5 …
│ ╟ 205a8d3 9 1.7845 0.58125 1.7381 … 5 …
│ ╟ dd23d96 8 1.8369 0.54173 1.7919 … 5 …
│ ╟ 5bb3a1f 7 1.8929 0.49108 1.8474 … 5 …
│ ╟ 6dc5610 6 1.951 0.43433 1.9046 … 5 …
│ ╟ a79cf29 5 2.0088 0.36837 1.9637 … 5 …
│ ╟ 5ea8327 4 2.0702 0.30388 2.025 … 5 …
│ ╟ bc0cf02 3 2.1338 0.23988 2.0883 … 5 …
│ ╟ f8cf03f 2 2.1989 0.17932 2.1542 … 5 …
│ ╟ 7575a44 1 2.2694 0.12833 2.223 … 5 …
├─╨ a72c526 0 2.3416 0.0959 2.2955 … 5 …
──────────────────────────────────────────────────────────────────────After modifying the code, data, or params, the same process can be resumed. DVC
recognizes the change and shows it (see experiment b363267):
$ vi train.py # modify code
$ vi params.yaml # modify params
$ dvc exp run
Modified checkpoint experiment based on 'exp-e15bc' will be created
...
$ dvc exp show --no-pager --no-timestamp ──────────────────────────────────────────────────────────────────────────────
Experiment step loss accuracy val_loss … epochs …
──────────────────────────────────────────────────────────────────────────────
workspace 13 1.5841 0.69262 1.5381 … 15 …
master - - - - … 5 …
│ ╓ exp-7ff06 13 1.5841 0.69262 1.5381 … 15 …
│ ╟ 6c62fec 12 1.6325 0.67248 1.5857 … 15 …
│ ╟ 4baca3c 11 1.6817 0.64855 1.6349 … 15 …
│ ╟ b363267 (2b06de7) 10 1.7323 0.61925 1.6857 … 15 …
│ ╓ 2b06de7 9 1.7845 0.58125 1.7381 … 5 …
│ ╟ 205a8d3 9 1.7845 0.58125 1.7381 … 5 …
│ ╟ dd23d96 8 1.8369 0.54173 1.7919 … 5 …
│ ╟ 5bb3a1f 7 1.8929 0.49108 1.8474 … 5 …
│ ╟ 6dc5610 6 1.951 0.43433 1.9046 … 5 …
│ ╟ a79cf29 5 2.0088 0.36837 1.9637 … 5 …
│ ╟ 5ea8327 4 2.0702 0.30388 2.025 … 5 …
│ ╟ bc0cf02 3 2.1338 0.23988 2.0883 … 5 …
│ ╟ f8cf03f 2 2.1989 0.17932 2.1542 … 5 …
│ ╟ 7575a44 1 2.2694 0.12833 2.223 … 5 …
├─╨ a72c526 0 2.3416 0.0959 2.2955 … 5 …
──────────────────────────────────────────────────────────────────────────────Sometimes you might need to train the model from scratch. The reset option
removes the checkpoint file before training: dvc exp run --reset.
Metrics logging
Continuously logging ML metrics is a very common practice in the ML world. Instead of a simple command-line output with the metrics values, many ML engineers prefer visuals and plots. These plots can be organized in a "database" of ML experiments to keep track of a project. There are many special solutions for metrics collecting and experiment tracking such as sacred, mlflow, weight and biases, neptune.ai, or others.
With DVC 2.0, we are releasing a new open-source library
DVC-Live that provides functionality for
tracking model metrics and organizing metrics in simple text files in a way that
DVC can visualize the metrics with navigation in Git history. So, DVC can show
you a metrics difference between the current model and a model in master or
any other branch.
This approach is similar to the other metrics tracking tools with the difference that Git becomes a "database" or of ML experiments.
Generate metrics file
Install the library:
$ pip install dvcliveInstrument your code:
import dvclive
from dvclive.keras import DvcLiveCallback
dvclive.init("logs") #, summarize=True)
...
model.fit(...
# Set up DVC-Live callback:
callbacks=[ DvcLiveCallback() ]
)
During the training you will see the metrics files that are continuously populated each epochs:
$ ls logs/
accuracy.tsv loss.tsv val_accuracy.tsv val_loss.tsv
$ head logs/accuracy.tsv
timestamp step accuracy
1613645582716 0 0.7360000014305115
1613645585478 1 0.8349999785423279
1613645587322 2 0.8830000162124634
1613645589125 3 0.9049999713897705
1613645590891 4 0.9070000052452087
1613645592681 5 0.9279999732971191
1613645594490 6 0.9430000185966492
1613645596232 7 0.9369999766349792
1613645598034 8 0.9430000185966492In addition to the continuous metrics files, you will see the summary metrics file and HTML file with the same file prefix. The summary file contains the result of the latest epoch:
$ cat logs.json | python -m json.tool
{
"step": 41,
"loss": 0.015958430245518684,
"accuracy": 0.9950000047683716,
"val_loss": 13.705962181091309,
"val_accuracy": 0.5149999856948853
}The HTML file contains all the visuals for continuous metrics as well as the summary metrics on a single page:
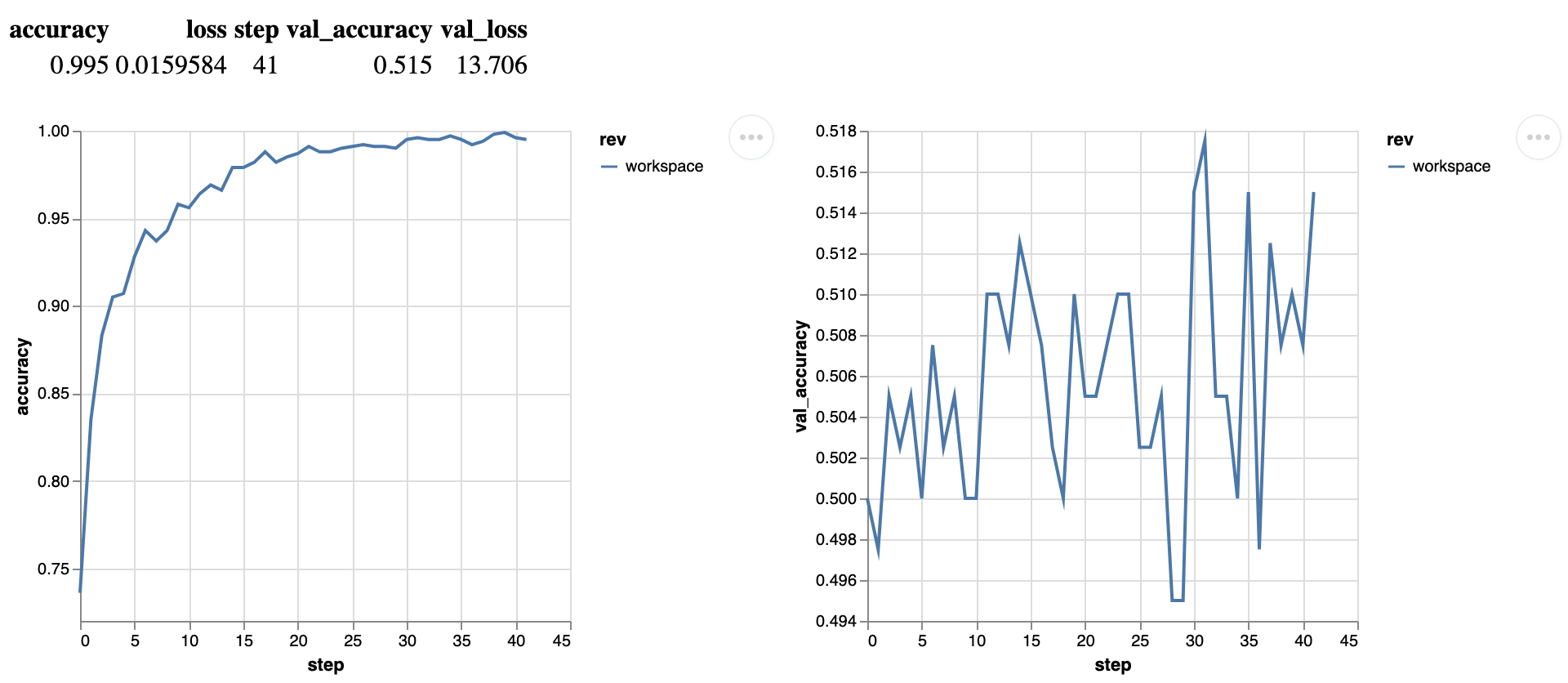
Note, the HTML and the summary metrics files are generating automatically for each. So, you can monitor model performance in realtime.
Git-navigation with the metrics file
DVC repository is NOT required to use the live metrics functionality from the above. It works independently from DVC.
DVC repository becomes useful when the metrics and plots are committed in your Git repository, and you need navigation around the metrics.
Metrics difference between workspace and the last Git commit:
$ git status -s
M logs.json
M logs/accuracy.tsv
M logs/loss.tsv
M logs/val_accuracy.tsv
M logs/val_loss.tsv
M train.py
?? model.h5
$ dvc metrics diff --target logs.json
Path Metric Old New Change
logs.json accuracy 0.995 0.99 -0.005
logs.json loss 0.01596 0.03036 0.0144
logs.json step 41 36 -5
logs.json val_accuracy 0.515 0.5175 0.0025
logs.json val_loss 13.70596 3.29033 -10.41563The difference between a particular commit/branch/tag or between two commits:
$ dvc metrics diff --target logs.json HEAD^ 47b85c
Path Metric Old New Change
logs.json accuracy 0.995 0.998 0.003
logs.json loss 0.01596 0.01951 0.00355
logs.json step 41 82 41
logs.json val_accuracy 0.515 0.51 -0.005
logs.json val_loss 13.70596 5.83056 -7.8754The same Git-navigation works with the plots:
$ dvc plots diff --target logs
file:///Users/dmitry/src/exp-dc/plots.html
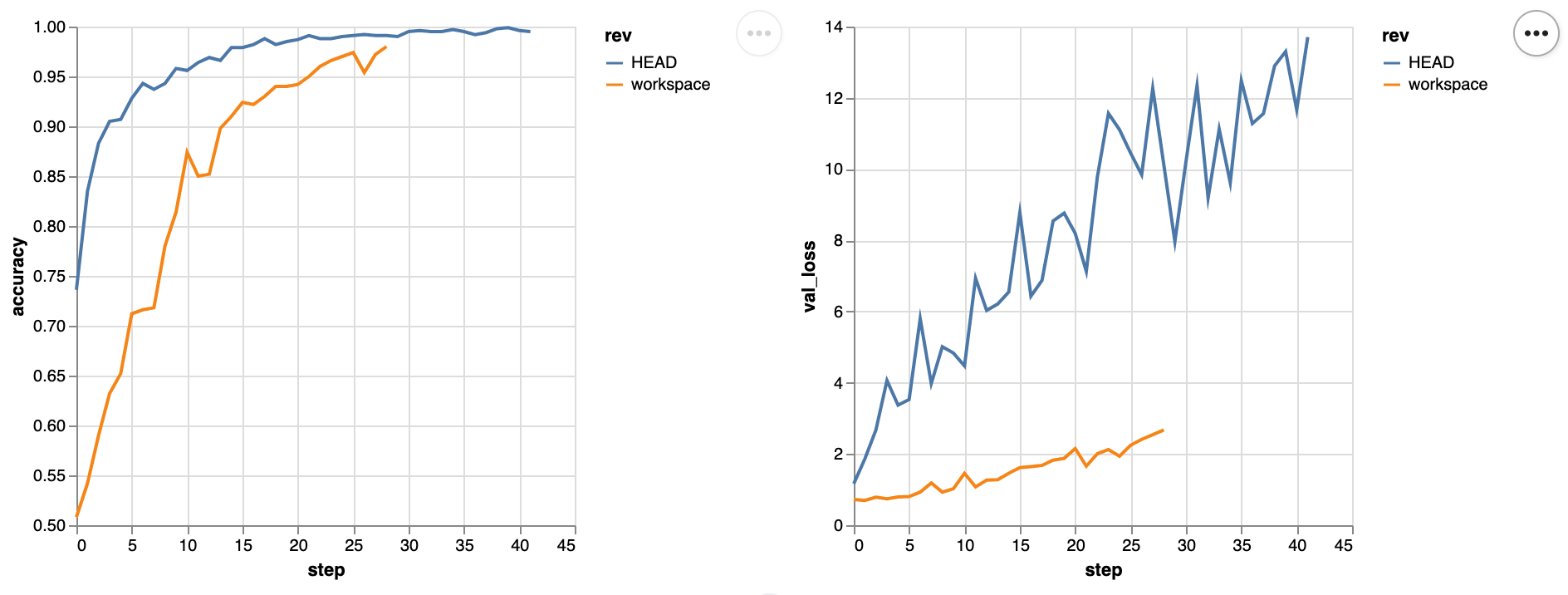
Another nice thing about the live metrics - they work across ML experiments and
checkpoints, if properly set up in dvc stages. To set up live metrics, you need
to specify the metrics directory in the live section of a stage:
stages:
train:
cmd: python train.py
live:
logs:
cache: false
summary: true
report: true
deps:
- dataThank you!
I'd like to thank all of you DVC community members for the feedback that we are constantly getting. This feedback helps us build new functionalities in DVC and make it more stable.
Please be in touch with us on Twitter and our Discord channel.