




DVC 1.0 release
Introduction
3 years ago, I was concerned about good engineering standards in data science: data versioning, reproducibility, workflow automation — like continuous integration and continuous delivery (CI/CD), but for machine learning. I wanted there to be a "Git for data" to make all this possible. So I created DVC (Data Version Control), which works as version control for data projects.
Technically, DVC codifies your data and machine learning pipelines as text metafiles (with pointers to actual data in S3/GCP/Azure/SSH), while you use Git for the actual versioning. DevOps folks call this approach GitOps or, more specifically, in this case DataOps or MLOps.
The new DVC 1.0. is inspired by discussions and contributions from our community of data scientists, ML engineers, developers and software engineers.
DVC 1.0
The new DVC 1.0 is inspired by discussions and contributions from our community — both fresh ideas and bug reports 😅. All these contributions, big and small, have a collective impact on DVC's development. I'm confident 1.0 wouldn't be possible without our community. They tell us what features matter most, which approaches work (and which don't!), and what they need from DVC to support their ML projects.
A few weeks ago we announced the 1.0 pre-release. After lots of helpful feedback
from brave users, it's time to go live. Now, DVC 1.0 is available with all the
standard installation methods including pip, conda, brew, choco, and
system-specific packages: deb, rpm, msi, pkg. See https://dvc.org/doc/install
for more details.
New features
It took us 3 years to finalize the requirements for DVC 1.0 and stabilize the commands (API) and DVC file formats. Below are the major lessons that we have learned in 3 years of this journey and how these are reflected in the new DVC.
Multi-stage DVC files
Our users taught us that ML pipelines evolve much faster than data engineering pipelines with data processing steps. People need to change the commands of the pipeline often and it was not easy to do this with the old DVC-files.
In DVC 1.0, the DVC metafile format was changed in three big ways. First,
instead of multiple DVC "stage files" (*.dvc), each project has a single
dvc.yaml file. By default, all stages go in this single YAML file.
Second, we made clear connections between the dvc run command (a helper to
define pipeline stages), and how stages are defined in dvc.yaml. Many of the
options of dvc run are mirrored in the metafile. We wanted to make it far less
complicated to edit an existing pipeline by making dvc.yaml more human
readable and writable.
Third, file and directory hash values are no longer stored in the pipeline metafile. This approach aligns better with the GitOps paradigms and simplifies the usage of DVC by tremendously improving metafile human-readability:
stages:
process:
cmd: ./process_raw_data raw_data.log users.csv
deps:
- raw_data.log
params:
- process_file
- click_threshold
outs:
- users.csv
train:
cmd: python train.py
deps:
- users.csv
params:
- epochs
- log_file
- dropout
metrics:
- logs.csv
- summary.json:
cache: false
outs:
- model.pklAll of the hashes have been moved to a special file, dvc.lock, which is a lot
like the old DVC-file format. DVC uses this lock file to define which data files
need to be restored to the workspace from data remotes (cloud storage) and if a
particular pipeline stage needs to be rerun. In other words, we're separating
the human-readable parts of the pipeline into dvc.yaml, and the auto-generated
"machine" parts into dvc.lock.
Another cool change: the auto-generated part (dvc.lock) doesn't necessarily
have to be stored in your Git repository. The new run-cache feature eliminates
the need of storing the lock file in Git repositories. That brings us to our
next big feature:
Run cache
We built DVC with a workflow in mind: one experiment to one commit. Some users love it, but this approach gets clunky fast for others (like folks who are grid-searching a hyperparameter space). Making Git commits for each ML experiment was a requirement with the old DVC, if you wanted to snapshot your project or pipelines on each experiment. Moving forward, we want to give users more flexibility to decide how often they want to commit.
We had an insight that data remotes (S3, Azure Blob, SSH etc) can be used
instead of Git for storing the codified meta information, not only data. In DVC
1.0, a special structure is implemented, the run-cache, that preserves the state
(including all the hashes). Basically, all the information that is stored in the
new dvc.lock file is replicated in the run-cache.
The advantage of the run-cache is that pipeline runs (and output file versions) are not directly connected to Git commits anymore. The new DVC can store all the runs in the run-cache, even if they were never committed to Git.
This approach gives DVC a "long memory" of DVC stages runs. If a user tries to run a stage that was previously run (whether committed to Git or not), then DVC can return the result from the run-cache without rerunning it. It is a useful feature for a hyperparameter optimization stage — when users return to the previous sets of the parameters and don't want to wait for ML retraining.
Another benefit of the run-cache is related to CI/CD systems for ML, which is a holy grail of MLOps. The long memory means users don't have to make auto-commits in their CI/CD system side - see this Stackowerflow question.
Plots
Countless users have asked when we'd support metrics visualizations. It became
clear that metrics and their visualization are an essential part of DataOps,
especially when it comes down to navigation around ML models, datasets and
experiments. Now it's here: DVC 1.0 introduces metrics file visualization
commands, dvc plots diff and dvc plots show. This is brand-new functionality
in DVC and it's in experimental mode now.
This function is designed not only for visualizing the current state of your project, but also for comparing plots across your Git history. Users can visualize how, for example, their model accuracy in the latest commit differs from another commit (or even multiple commits).
$ dvc plots diff -d logs.csv HEAD HEAD^ d1e4d848 baseline_march
file:///Users/dmitry/src/plot/logs.csv.html
$ open logs.csv.html
$ dvc plots diff -d logs.csv HEAD HEAD^ d1e4d848 baseline_march \
-x loss --template scatter
file:///Users/dmitry/src/plot/logs.csv.html
$ open logs.csv.html
DVC plots are powered by the Vega-Lite graphic library. We picked Vega because it's high-level to manipulate, compatible with all ML frameworks, and looks great out of the box. However, you don't have to know Vega to use DVC plots: we've provided default templates for line graphs, scatterplots, and confusion matrices, so you can just point DVC plots to your metrics and go.
Data transfer optimizations
In DataOps, data transfer speed is hugely important. We've done substantial
work to optimize data management commands, like
dvc pull / push / status -c / gc -c. Now, based on the amount of data to move,
DVC can choose the optimal strategy for traversing your data remote.
Mini-indexes help DVC instantly check data directories instead of iterating over millions of files. This also speeds up adding/removing files to/from large directories.
More optimizations are included in the release based on our profiling of performance bottlenecks. More detailed benchmark reports show how many seconds it takes to run specific commands on a directory containing 2 million images.

Hyperparameter tracking
This feature was actually released in the last DVC 0.93 version (see the params docs. However, it is an important step to support configuration files and ML experiments in a more holistic way.
The parameters are a special type of dependency in the pipelines. This is the
way of telling DVC that a command depends not on a file (params.yaml) but on a
particular set of values in the file:
$ dvc run -d users.csv -o model.pkl \
--params lr,train.epochs,train.layers \
python train.pyThe params.yaml file is the place where the parameters are stored:
lr: 0.0041
train:
epochs: 70
layers: 9
process:
thresh: 0.98
bow: 15000Stable releases cycles
Today, many teams use DVC in their daily job for modeling and as part of their production MLOps automation systems. Stability plays an increasingly important role.
We've always prioritized agility and speed in our development process. There have been weeks with two DVC releases! This approach had a ton of benefits in terms of learning speed and rapid feedback from users.
Now we're seeing signs that it's time to shift gears. Our API is stabilized and version 1.0 is built with our long-term vision in mind. Our user-base has grown and we have footing with mature teams - teams that are using DVC in mission-critical systems. That's why we're intentionally going to spend more time on release testing in the future. It might increase the time between releases, but the quality of the tool will be more predictable.
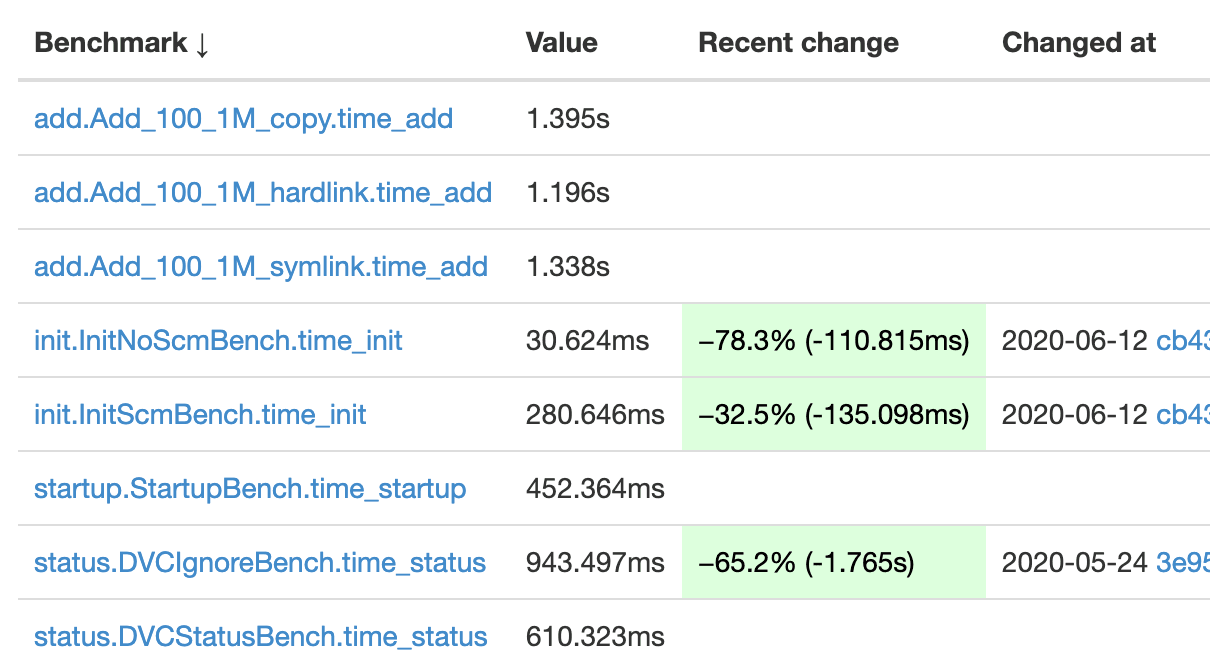
Additionally, we've already implemented a benchmark testing framework to track performance across potential releases: https://iterative.github.io/dvc-bench/ In this website, anyone can see the performance improvements and degradations for every release candidate:
For more information on the new features…
Each of these new features has a story that could fill a separate blog post - so that's what we'll be doing. We'll be posting more soon. Peter Rowlands will be writing a blog post about the performance optimization in DVC 1.0, Paweł Redzyński about versioning and visualizing plots, Saugat Pachhai about the new DVC file formats and pipelines, and Ruslan Kuprieiev about run-cache.
Please stay in touch and subscribe to our newsletter in http://dvc.org.
Thank you!
It's quite a journey to build an open source project in the ML/AI space. We're fortunate to have a community of DVC users, contributors and cheerleaders. All these folks tremendously help us to define, test and develop the project. We've reached this significant milestone of version 1.0 together and I hope we'll continue working on DVC and bringing the best practices of DataOps and MLOps to the ML/AI space.
Thank you again! And please be in touch on Twitter, and our Discord channel.