




Hi there! This is Gema! Today I'll be the guide to Community Gems for August. Big shout out to Milecia Mcgregor that co-authors this post.
If I am tracking a directory with DVC, how can I read the file names without using dvc checkout?
This is a wonderful question from @Mikita Karotchykau!
You can read those file names with our DVC Python API. Here's an example of how that may work:
import os
from dvc.repo import Repo
for item in Repo.ls(
"<repo_path_or_url>",
"/path/to/dir",
dvc_only=True,
rev="<rev>",
recursive=True
):
print(os.path.join("/path/to/dir", item["path"]))How can I mock the execution of certain stages in dvc repro?
Nice situation posted as a question from @JesusCerquides!
This situation might arise when you have stages that take a long time to run or when you are confident about them and want to advance with the pipeline design; therefore, you wouldn't want to reproduce all again. One example might be when you have a good enough feature engineering and want to iterate over hyperparameters in training.
You should be able to run dvc commit in this case as it provides a way to
complete dvc repro when it has been used with the --no-commit or --no-exec
options. Those options cause the command to skip certain stages so you can move
to another stage without executing all of them.
How can I change the dataset for a DVC pipeline that runs completely with dvc repro?
Great question from @5216!
One of the straightforward solutions for this challenge is to replace the
dataset in place and run dvc repro again. If the dataset is at some other
path, you can update dvc.yaml to use that new path instead of the original
dataset path. If you don't want to lose the previous pipeline and want to keep
it and results for future reproducibility or other needs, you can use
dvc exp run as it keeps a record in Git of all changes and allows you to
create a branch if needed.
When I trigger a GitHub event, I use pull_request: types: [labeled] and it seems to cause the runner to use the wrong SHA. How can I fix this?
Thanks for the good question @hyojoo!
You might have encounter that this issue doesn´t allow you to send comments to the PR. A change with respect to the SHAs made us point to the head reference.
We've updated CML Start to include a fix:
- uses: actions/checkout@v3
with:
ref: ${{ github.event.pull_request.head.sha }}How does DVC solve the file versioning problem, specifically when we want to roll back to previous versions of the dataset?
Time travel with DVC ! We just find this topic fascinating. Thanks for bringing this up @MiaM
git checkout command lets us restore any commit in the repository history. It
will automatically adjust the repository files, by replacing, adding or deleting
them. This git command changes dvc.lock and another DVC files, meaning that
git tracks DVC files, but doesn´t track the file per se. For this to happen and
get back to previous versions of the dataset, make sure to dvc checkout on
this one.
For reproducibility, we will see now what happens with the data.dvc file and
cache folder when we go back to a previous dataset version. For that, we will
add a dataset, change it and add it to DVC, and then get back to the first
dataset version.
First, we have added a dataset, and then add it as well with DVC: if we explore
the data.xml.dvc file and the cache folder , we will see the MD5 hash for the
file, a unique identifier!
$ cat data.xml.dvc # will show file info including MD5 hash
outs:
- md5: a8d60da582524dac805fc7b64d762e58
size: 33471
path: data.xml
$ cd .dvc/cache
$ tree # will show dataset in the cache with hash reference
.
|___ a8
|___ a8d60da582524dac805fc7b64d762e58
After changing the dataset, we have added it to DVC as well. As you can see in
data.xml.dvc file, the hash MD5 has changed, as the dataset is different! The
cache , however keeps both hashes. Smart!
$ cat data.xml.dvc # will show new file info including MD5 hash
outs:
- md5: 8e4ed00d7118e31340db6c0ba572658e
size: 35263
path: data.xml
$ cd .dvc/cache
$ tree # will show both datasets in the cache with their hash reference
.
|___ 8e
| |___ 4ed00d7118e31340db6c0ba572658e
|___ a8
|___ d60da582524dac805fc7b64d762e58Now let´s get back to the previous version of the dataset
$ git checkout HEAD~1 data/data.xml.dvc
$ dvc checkout
$ git commit data/data.xml.dvc$ cat data.xml.dvc
outs:
- md5: a8d60da582524dac805fc7b64d762e58
size: 33471
path: data.xmlInteresting! The hash makes reference to the previous version of our dataset
that has been stored in our cache folder. The cache folder saves the data so DVC
allows you to get back to previous files with the synced git checkout and
dvc checkout commands. Please note that you have to checkout with Git, but
also with DVC! If you always want to ensure dvc checkout after git checkout
you can use post-chekout
Git hook to
automatically update the workspace with the correct data file versions.

How can I plot the result metrics for the machine learning experiments inside VSCode DVC extension scenario?
Happy to discover that you are using DVC extension for VSCode @Julian_ !
You can define your plots with
DVCLive depending on your
machine learning challenge and save them as a CSV, JSON file or other
supported format.
You need to list it as a plots output in dvc.yaml, adding plots in the build
stage
stages:
build:
cmd: python train.py
deps:
- features.csv
outs:
- model.pt
metrics:
- metrics.json:
cache: false
plots:
- metrics.csv: # specify the name and .csv extension file
cache: false[Im constructing a pipeline with several stages inside the dvc.yaml file.
When I execute dvc exp run or dvc repro commands, stages run randomly. What is the reason behind this or did I miss something ?] (https://discord.com/channels/485586884165107732/563406153334128681/1011617355849269258)
Hello there @ekmekci48 ! That is indeed a really great question.
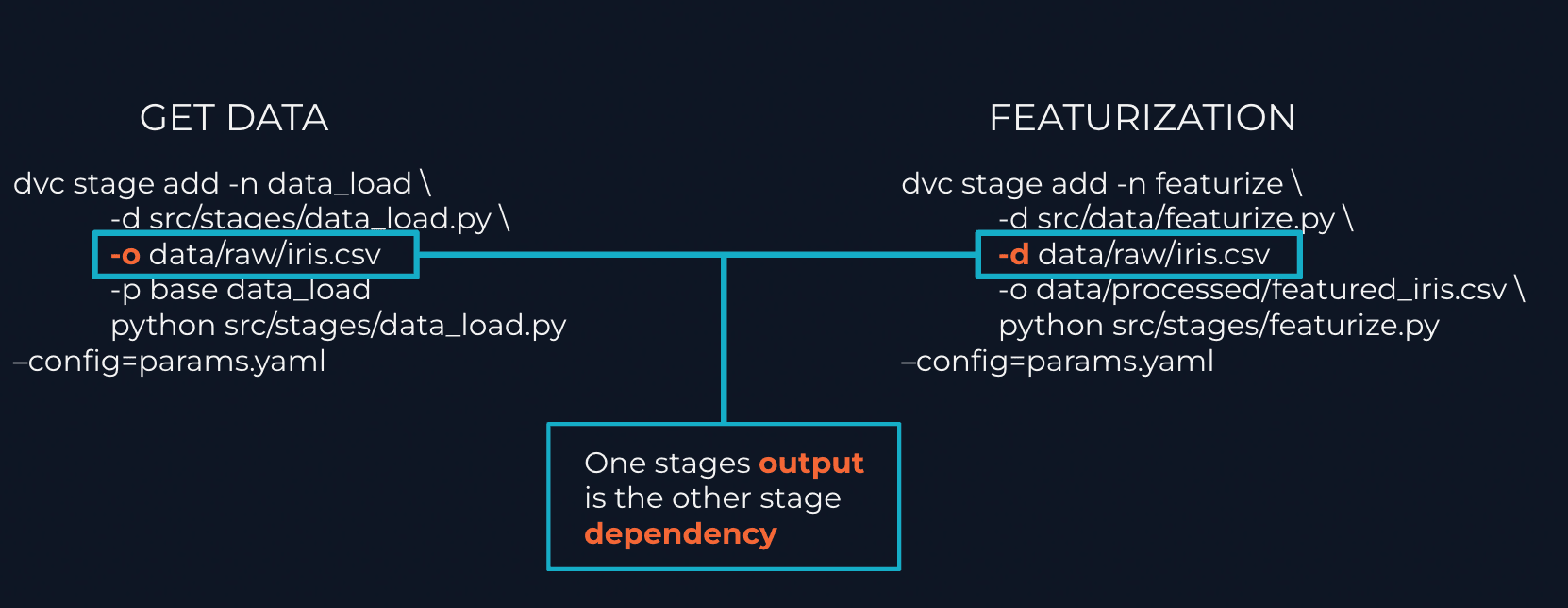
In order to ensure linear order in your pipeline, you should concatenate all your pipeline stages, taking into account that the previous stage output will be the next dependency, from the beginning to the end of your pipeline. Please make sure that you specify dependencies and outputs for each stage: that will introduce the order to provide an end result. For stages that don´t depend on each other, they will still executed randomly.
As an example, imagine that we have 3 stages: load , feature engineering and training. Load output with be feature engineering dependency, and feature engineering output will be training dependency.
The key concept to have into account here is that you should concatenate the output of one stage as the dependency of the other among all pipeline stages.
As an example, added some schema from our learning
course: check out the -o and -d config flags
. Those will be key for concatenating your stages.
Let's also thank @daavoo for helping you out pointing to the docs on this one!
Please check out the docs to know more!

Keep an eye out for our next Office Hours Meetup! Make sure you stay up to date with us to find out what it is! Join our group to stay up to date with specifics as we get closer to the event!
Check out our docs to get all your DVC, CML, and MLEM questions answered!
Join us in Discord to chat with the community!