ML Model Ensembling with Fast Iterations
In many real-world Machine Learning projects, there is a need to ensemble complex models as well as maintain pipelines. As we will demonstrate, DVC is a good tool that helps tackling common technical challenges of building pipelines for the ensemble learning.





In a model ensembling setup, the final prediction is a composite of predictions
from individual machine learning algorithms. To make the best model composite,
you have to try dozens of combinations of weights for the model set. It takes a
lot of time to come up with the best one. That is why the iteration speed is
crucial in the ML model ensembling. We are going to make our research
reproducible by using Data Version Control tool -
(DVC). It provides the ability to quickly re-run and replicate
the ML prediction result by executing just a single command dvc repro.
As we will demonstrate, DVC is a good tool that helps tackling common technical challenges of building pipelines for the ensemble learning.
Project Overview
In this case, we will build an R-based solution to attack the supervised-learning regression problem to predict win sales per Predict Wine Sales Kaggle competition.
An ensemble prediction methodology will be used in the project. The weighted
ensemble of three models will be implemented, trained, and predicted from
(namely, these are Linear Regression, GBM, and XGBoost).
If properly designed and used, ensemble prediction can perform much better then predictions of individual machine learning models composing the ensemble.
Prediction results will be delivered in a format of output CSV file that is specified in the requirements to the Predict Wine Sales Kaggle competition (so called Kaggle submission file).
Important Pre-Requisites
In order to try the materials of this repository in your environment, the following software should be installed on your machine
-
Python 3 runtime environment for your OS (it is required to run DVC commands in the batch files)
-
DVC itself (you can install it as a python package by simply doing the standard command in your command line prompt:
pip install dvc) -
R 3.4.x runtime environment for your OS
-
git command-line client application for your OS
Technical Challenges
The technical challenges of building the ML pipeline for this project were to meet business requirements below
-
Ability to conditionally trigger execution of 3 different ML prediction models
-
Ability to conditionally trigger model ensemble prediction based on predictions of those 3 individual models
-
Ability to specify weights of each of the individual model predictions in the ensemble
-
Quick and fast redeployment and re-run of the ML pipeline upon frequent reconfiguration and model tweaks
-
Reproducibility of the pipeline and forecasting results across the multiple machines and team members
The next sections below will explain how these challenges are addressed in the design of ML pipeline for this project.
ML Pipeline
The ML pipeline for this project is presented in the diagram below
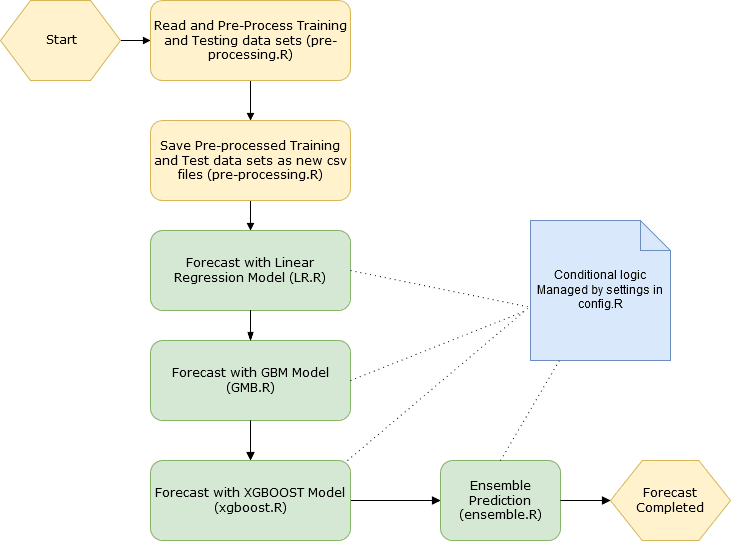
As you can see, the essential implementation of the solution is as follows
-
preprocessing.Rhandles all aspects of data manipulations and pre-processing (reading training and testing data sets, removing outliers, imputing NAs etc.) as well as stores refined training and testing set data as new files to reuse by model scripts -
3 model scripts implement training and forecasting algorithms for each of the models selected for this project (
LR.R,GBM.R,xgboost.R) -
ensemble.Ris responsible for the weighted ensemble prediction and the final output of the Kaggle submission file -
config.Ris responsible for all of the conditional logic switches needed in the pipeline (it is included as a source to all of modeling and ensemble prediction scripts, to get this done)
There is a special note about lack of feature engineering for this project. It was an intended specification related to the specifics of the dataset. The existing features were quite instrumental to predict the target values ‘as is’. Therefore it had been decided to follow the well-known Pareto principle (interpreted as “20% of efforts address 80% of issues”, in this case) and not to spend more time on it.
Note: all R and batch files mentioned throughout this blog post are
available online in a separate GitHub
repository. You will be also able
to review more details on the implementation of each of the machine learning
prediction models there.
Pipeline Configuration Management
All of the essential tweaks to conditional machine learning pipeline for this
project is managed by a configuration file. For ease of its use across solution,
it was implemented as an R code module (config.R), to be included to all model
training and forecasting. Thus the respective parameters (assigned as R
variables) will be retrieved by the runnable scripts, and the conditional logic
there will be triggered respectively.
This file is not intended to run from a command line (unlike the rest of the R scripts in the project).
| # Competition: https://inclass.kaggle.com/c/pred-411-2016-04-u3-wine/ | |
| # This is a configuration file to the entire solution | |
| # LR.R specific settings | |
| cfg_run_LR <- 1 # if set to 0, LR model will not fit, and its prediction will not be calculated in the batch mode | |
| # GMB.R specific settings | |
| cfg_run_GBM <- 1 # if set to 0, GBM model will not fit, and its prediction will not be calculated in the batch mode | |
| # xgboost.R specific settings | |
| cfg_run_xgboost <- 1 # if set to 0, xgboost model will not fit, and its prediction will not be calculated in the batch mode | |
| # ensemble.R specific settings | |
| cfg_run_ensemble <- 1 # if set to 0, the ensemble will not predict, and ensemble prediction will not be created | |
| # ensemble components | |
| cfg_model_predictions <- c("data/submission_LR.csv", "data/submission_GBM.csv", "data/submission_XGBOOST.csv") | |
| # element weights mapped to the cfg_model_predictions elements above | |
| cfg_model_weights <- c(1,1,1) # weights of predictions of the models in the ensemble |
Why Do We Need DVC?
As we all know, there is no way to build the ideal ML model with sound prediction accuracy from the very beginning. You will have to continuously adjust your algorithm/model implementations based on the cross-validation appraisal until you yield the blooming results. This is especially true in the ensemble learning where you have to constantly tweak not only parameters of the individual prediction models but also the settings of the ensemble itself
-
changing ensemble composition — adding or removing individual prediction models
-
changing model prediction weights in the resulting ensemble prediction
Under such a condition, DVC will help you to manage your ensemble ML pipeline in a really solid manner. Let’s consider the following real-world scenario
-
Your team member changes the settings of
GBMmodel and resubmit its implementation to (this is emulated by the commit #8604103f0, check sum27825d0) -
You rerun the entire ML pipeline on your computer, to get the newest predictions from
GBMas well as the updated final ensemble prediction -
The results of the prediction appeared to be still not optimal thus someone changes the weights of individual models in the ensemble, assigning
GBMhigher weight vs.xgboostandLR -
After the ensemble setup changes committed (and updated
config.Rappeared in the repository, as emulated by the commit #eb97612ce, check sum5bcbe11), you re-run the model predictions and the final ensemble prediction on your machine once again
All that you need to do to handle the changes above is simply to keep running your DVC commands per the script developed (see the section below). You do not have to remember or know explicitly the changes being made into the project codebase or its pipeline configuration. DVC will automatically check out latest changes from the repo as well as make sure it runs only those steps in the pipeline that were affected by the recent changes in the code modules.
Orchestrating the Pipeline : DVC Command File
After we developed individual R scripts needed by different steps of our Machine Learning pipeline, we orchestrate it together using DVC.
Below is a batch file illustrating how DVC manages steps of the machine learning process for this project
| # This is a DVC-based script to manage machine-learning pipeline for a project per | |
| # https://inclass.kaggle.com/c/pred-411-2016-04-u3-wine/ | |
| mkdir R_DVC_GITHUB_CODE | |
| cd R_DVC_GITHUB_CODE | |
| # clone the github repo with the code | |
| git clone https://github.com/gvyshnya/DVC_R_Ensemble | |
| # initialize DVC | |
| $ dvc init | |
| # import data | |
| $ dvc import https://inclass.kaggle.com/c/pred-411-2016-04-u3-wine/download/wine.csv data/ | |
| $ dvc import https://inclass.kaggle.com/c/pred-411-2016-04-u3-wine/download/wine_test.csv data/ | |
| # run data pre-processing | |
| $ dvc run Rscript --vanilla code/preprocessing.R data/wine.csv data/wine_test.csv data/training_imputed.csv data/testing_imputed.csv | |
| # run LR model fit and forecasting | |
| $ dvc run Rscript --vanilla code/LR.R data/training_imputed.csv data/testing_imputed.csv 0.7 825 data/submission_LR.csv code/config.R | |
| # run GBM model fit and forecasting | |
| $ dvc run Rscript --vanilla code/GBM.R data/training_imputed.csv data/testing_imputed.csv 5000 10 4 25 data/submission_GBM.csv code/config.R | |
| # rum XGBOOST model fit and forecasting | |
| $ dvc run Rscript --vanilla code/GBM.R data/training_imputed.csv data/testing_imputed.csv 1000 10 0.0001 1.0 data/submission_xgboost.csv code/config.R | |
| # prepare ensemble submission | |
| # Note: please make sure to edit your code/config.R to set up the references to the predictions from each model according | |
| # to the names of output files on the steps above | |
| $ dvc run Rscript --vanilla code/ensemble.R data/submission_ensemble.csv code/config.R |
If you then further edit ensemble configuration setup in code/config.R, you
can simply leverage the power of DVC as for automatic dependencies resolving and
tracking to rebuild the new ensemble prediction as follows
| # Improve ensemble configuration | |
| $ vi code/config.R | |
| # Commit all the changes. | |
| $ git commit -am "Updated weights of the models in the ensemble" | |
| # Reproduce the ensemble prediction | |
| $ dvc repro data/submission_ensemble.csv |
Summary
In this blog post, we worked through the process of building an ensemble prediction pipeline using DVC. The essential key features of that pipeline were as follows
-
reproducibility — everybody on a team can run it on their premise
-
separation of data and code — this ensured everyone always runs the latest versions of the pipeline jobs with the most up-to-date ‘golden copy’ of training and testing data sets
The helpful side effect of using DVC was you stop keeping in mind what was changed on every step of modifying your project scripts or in the pipeline configuration. Due to it maintaining the dependencies graph (DAG) automatically, it automatically triggered the only steps that were affected by the particular changes, within the pipeline job setup. It, in turn, provides the capability to quickly iterate through the entire ML pipeline.
As DVC brings proven engineering practices to often suboptimal and messy ML processes as well as helps a typical Data Science project team to eliminate a big chunk of common DevOps overheads, I found it extremely useful to leverage DVC on the industrial data science and predictive analytics projects.